网站内容采集(百度推出“飓风算法”,哪些内容算是恶劣采集? )
优采云 发布时间: 2021-12-15 02:38网站内容采集(百度推出“飓风算法”,哪些内容算是恶劣采集?
)
2017年7月7日,百度正式上线“飓风算法”。根据官方文档,飓风算法的目标是网站,而不是网页;主要是针对采集的不良内容作为网站的主要来源,并不是所有收录不良内容的网站。
哪些内容被认为是不好的采集?不好的采集内容一般是指不花时间、精力、专业能力、人工整合的内容,或者对用户没有任何附加价值的内容。
一、这部分内容有以下几种:
1、来自其他网站的内容采集
包括整个页面内容为采集,主题内容为采集,或多条采集拼凑而成。这种类型的内容很容易识别。
2、采集 后期轻度处理的内容
包括一些词句的修改,或者词批替换的使用(一些伪原创工具)。这种类型的识别稍微困难一些。
3、来自一些动态网站的内容采集
包括来自其他搜索引擎的采集 搜索结果,采集 新闻提要流。
注意几点:主要内容,不好的采集,附加值。
二、什么内容还不错采集?
为什么有些网站属于采集却不受影响,比如某个doc,某个wave。其实只要达到了一定的点,就还不错采集,重点是:给用户带来附加值。有两种类型的附加值:站点增益和内容增益。这时候可以引用百度搜索技术博客《谈网页价值》的一段话:
有人发表了一篇关于新闻事件的原创博客,后来被新浪转发到新闻频道。从描述的内容来看,这是一种重复。但这种重复只是主要内容的重复。一方面,它的转载带来了访问速度和稳定性的提升,后续检索用户可以通过“新闻事件+新浪”检索该新闻。这可以称为站点增益。另一方面,在转载过程中可能会更改页面标题,根据受众的不同,转载页面上可能会有更多有价值的评论和回复,也可能有指向其他相关事件的新闻。关联。这些可以称为内容增益。因此,即使题材内容没有变化,新浪的这篇转载也是有价值的,其稀缺性也很高。
同样的,另一方面,如果转载的网站是相当不知名的,它也不会带来站点名称/稳定性/速度增益。更有什者,转载后,在页面添加大量广告阻碍阅读,或仅转载部分内容不完整,此类转载,或采集,纯属重复,与采集相比与来源,没有搜索价值。
综上所述,对于主要内容重复的页面,我们应该评估是否有站点增益和内容增益。只有大量重复的页面根本没有增益,我们才应该认为它们的稀缺性很低。
三、这里的要点是:页面价值,增益
所以,只要能给用户带来网站收益、内容收益、附加值,就说明这个网页有自己独特的价值,不会受到飓风算法的打击。自从百度推出“飓风算法”以来,这些熟悉的网站都是最先被招募的。
7月7日拍摄网站,大部分是范文
7月6日拍摄网站,大部分是范文
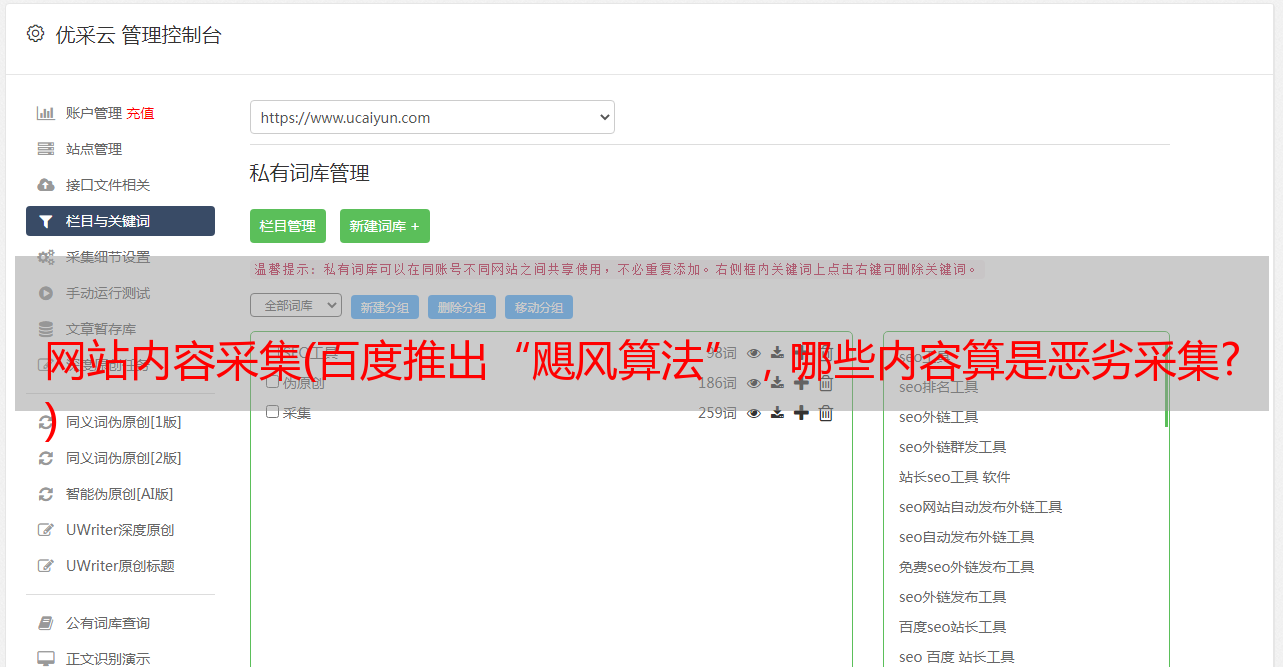
躺*敏*感*词*案例:
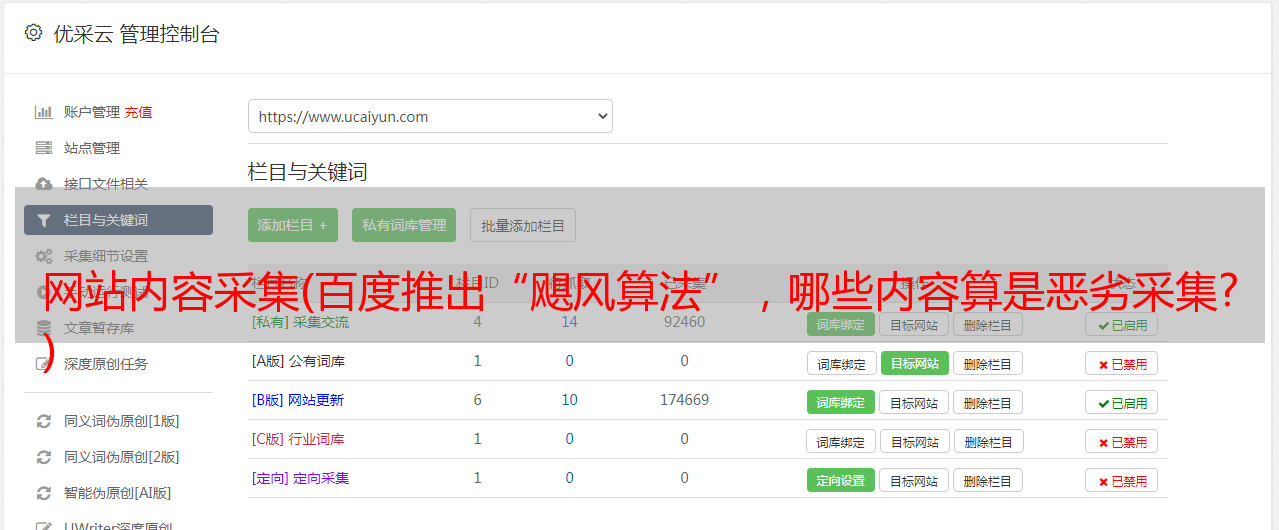
躺*敏*感*词*案例:
受飓风算法影响怎么办?
飓风算法主要针对一文不值的采集,一旦招进来,就无解了。不小心受伤的优质原创可以通过反馈中心申诉。
所以,一旦被飓风算法击中,只要不是明显的意外受伤,短期内是没有办法解决的。(被搜索引擎算法命中很常见,如果不被搜索引擎接受,一般是没有办法申诉的,谷歌也是一样,只有人工处理才能申诉。)
如何避免被飓风算法击中
采集会被算法惩罚,内容完全是原创,成本很高。如何在不受飓风算法惩罚的情况下生成内容。事实上,解决方案是专注于内容增益。有几种解决方案:
1、添加用户评论模块
页面中添加了用户评论模块。当有用户评论时,评论内容也会成为页面内容的一部分,产生附加价值。作为用户,在阅读完内容后,他也希望看到真实用户的意见,比如内容是否真实、信息是否无效、是否有额外提醒等。 不过需要注意的是评论的内容最好在源码中实现,而不是在JS中(方便搜索引擎识别)。
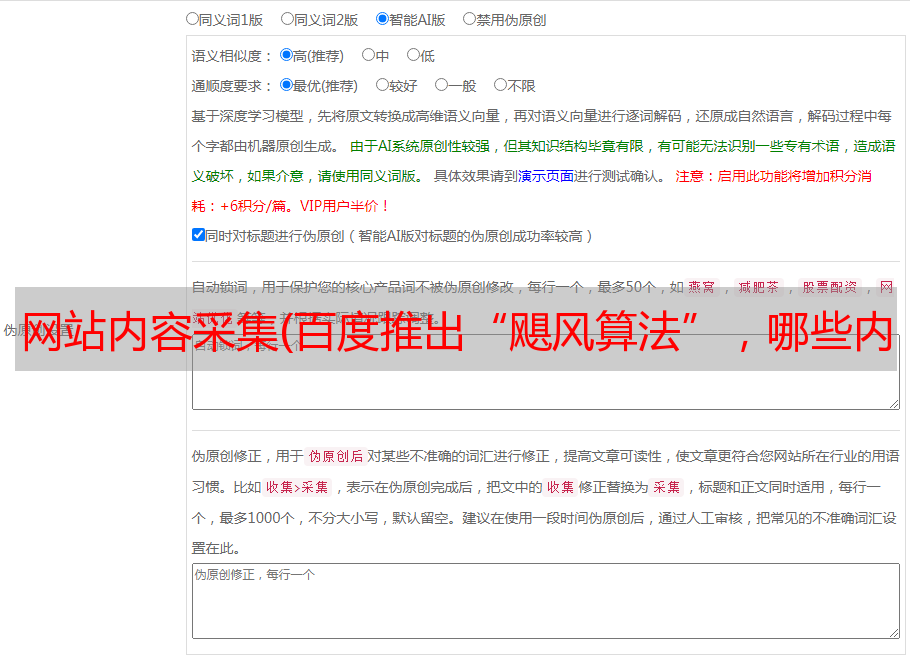
示例:网易新闻主题
2、添加内容推荐模块
根据网页主题,添加相关内容模块,如延伸阅读、往期报道、相关阅读等。关于“张艺兴”,你可以了解到他之前参加过哪些活动,有哪些绯闻,参加过极限挑战的进度,这些对用户来说都是非常有价值的。实现思路:一是手工编辑;另一种是算法实现,比如根据TF-IDF提取主体关键词,然后用关键词匹配历史内容。