php 爬虫抓取网页数据(闲人日记:如何获取交叉熵函数的开发者工具?(上) )
优采云 发布时间: 2021-12-02 02:08php 爬虫抓取网页数据(闲人日记:如何获取交叉熵函数的开发者工具?(上)
)
闲人日记
时间:2021年3月9日
这上来明明很闲却没更新!怎么说呢,不想做,总能找到很多理由。毕竟,“不想做”就是“不想做”。停止废话,开始进入主题。
打开网站 主页进行实验。可以看到网页上有一个明显的表格。这张表是看到别人写交叉熵函数文章时搬过来的数据。接下来,我们将尝试使用Python获取以下数据,并使用不同色块的类属性作为行索引。
看看数据就知道了
接下来F12打开浏览器的开发者工具,我们先看一下网页的源码,这可以帮助我们分析之后如何处理数据。但是在开始之前,笔者首先要说的是,编写爬虫没有固定的、具体的方法,一定要“具体情况具体分析”!很多时候我们面对的需求是不一样的,有些网站不能用下面的方法获取数据(获取的方法会有很大的不同),这些都需要很多具体的经验和处理具体的人脸。问题的经验。. .
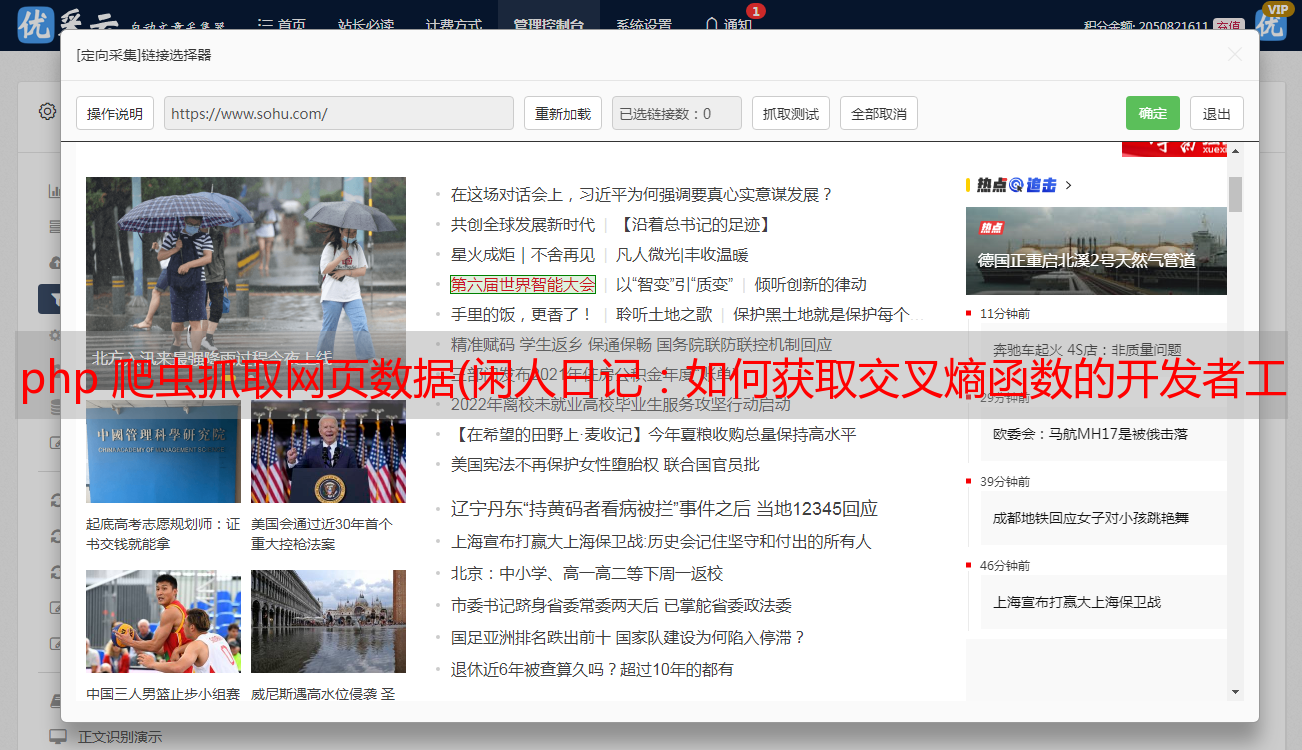
点击元素选择工具,点击目标元素,查看器跳转到目标元素的代码。见图一。
图一
一起来看看元素之间的“父子关系”吧!左边的“代”比较大,其中,图2这个...里面是我们要获取数据的目标表的源代码,我们发现只有这个表出现了在整个网页中。class=table table-hover 参数类的属性值,这将是脚本找到这个表对象的重要依据。
图二
为了演示方便,只列出了tbody的6个tr
好的,我们接下来开始我们的工作。首先,我们要先安装一些爬虫相关的库或模块。如果没有安装,可以在cmd中输入命令安装:pip install requests beautifulsoup4 pandas(requests和beautifulsoup4、pandas也安装了)。安装成功后,我们进入下一步。打开 Jupyther Notebook,数据科学中常用的 Python 集成开发环境。如果使用Python的IDLE工具,最好一行一行的输入命令,否则很容易报错。
分别导入请求和beautifulsoup4、pandas:
对于网络请求,某些网站必须带头发送,否则无法获取。
输入response.text,你会发现所有的汉字都变成了乱码。这时候就需要转换编码了。查看输出的编码:
响应文本
一般我们只需要将编码转换为utf-8即可解决中文乱码:
或输入以下代码:
处理完编码问题后
可以看出,相当杂乱,和真正的源码不太一样。“\r”表示当前位置返回到开头,“\n”表示换行,“\t”表示跳到下一个制表符位置。所以要创建一个 bs4.BeautifulSoup 类型的对象:
将文本转换为源代码
BeautifulSoup 模块使响应文本更加规则。
在变量soup“table table-hover”中找到第一个属性类的值为table的代码块:
...代码块
获取tbody中所有tr标签的代码块:
全部在tbody...
代码块列表
处理成所需数据的结构(警告!下面有很多图带你看代码):
列
上校
因为 attrs['class'] 返回一个列表
提取list对象中的字符串(否则tbody_id不能作为索引)
主题数据
将列表数据转换为pandas DataFrame 类型的数据
数据表
请根据自己的需要设计。这几乎是结束了。如果要将数据表导出为Excel表格,只需要使用pandas的to_excel()函数即可。
背后的故事
18年,笔者和数学建模的小伙伴遇到一个课题,需要采集大量的足球彩票网站数据进行数据分析。那时我们用的是matlab,对互联网技术或编程了解不多。水平也有待提高。所以我用了最慢的方法,一页一页地采集页面。可以说是慢到让人吐血。那是我第一次通宵工作。如果你现在看,你有更多的选择。
后记
笔者在百度体验中遇到过很多墙,文章还是发不出来。我总是被告知我已经踏上了“雷区”以做出改变。做了几个小时的更改,我仍然无法通过。不得不放弃。之前微信公众号上发的内容没人看,虽然只是比较基础的内容,自然会和别人的代码有很多相似之处。但无论如何,我是在自己的网站上爬取数据,而那个网站只是用于各种实验。
今天突然发现b站的专栏增加了一些作者和其他朋友之前一直在说的功能,有点惊喜!我爱小破站(poyin)。

