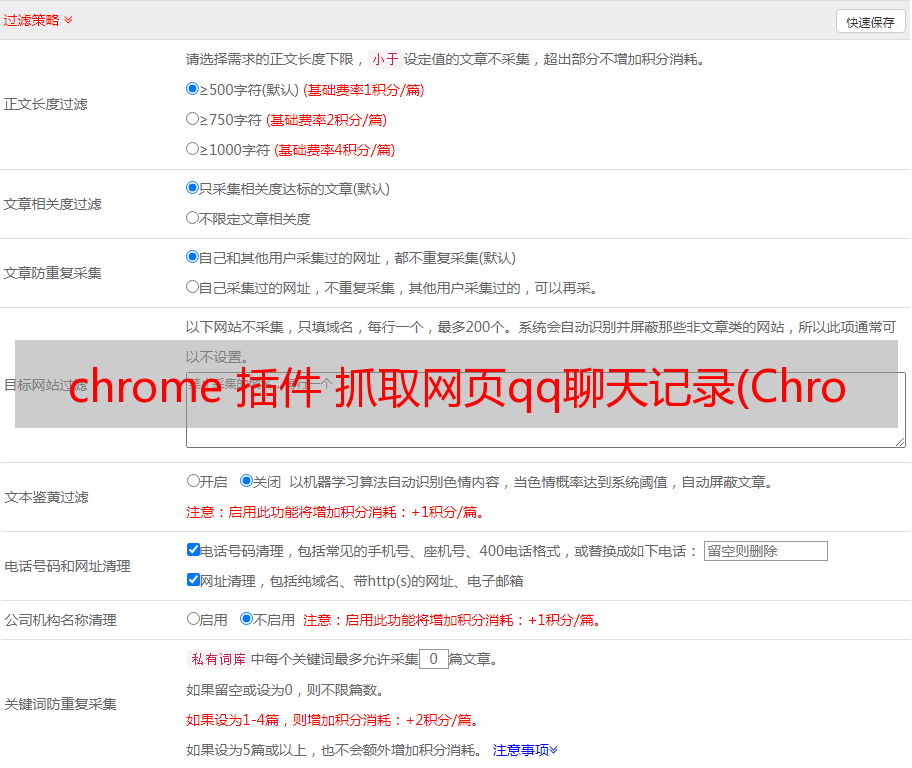
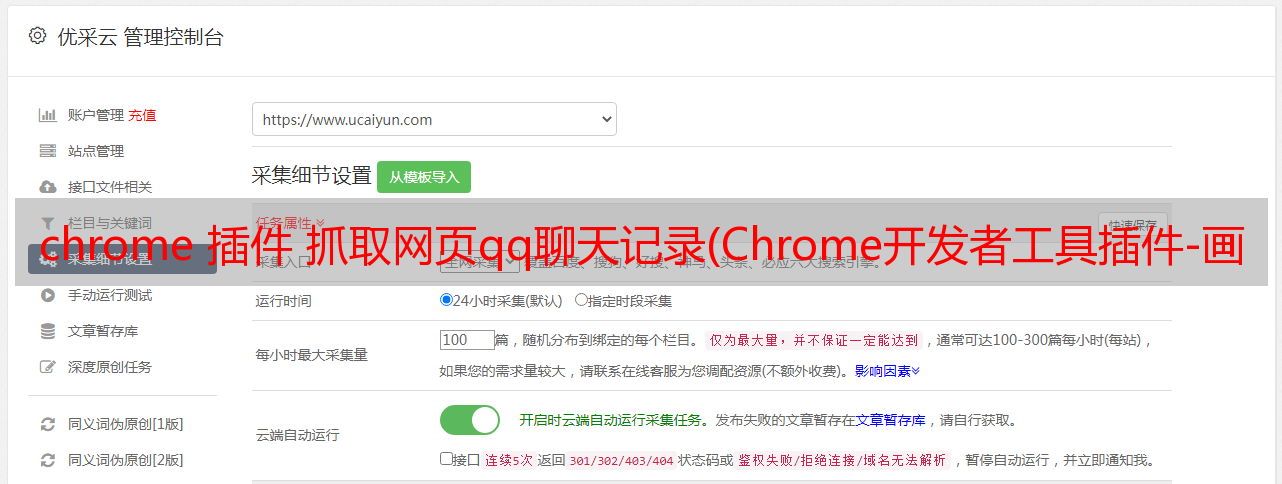
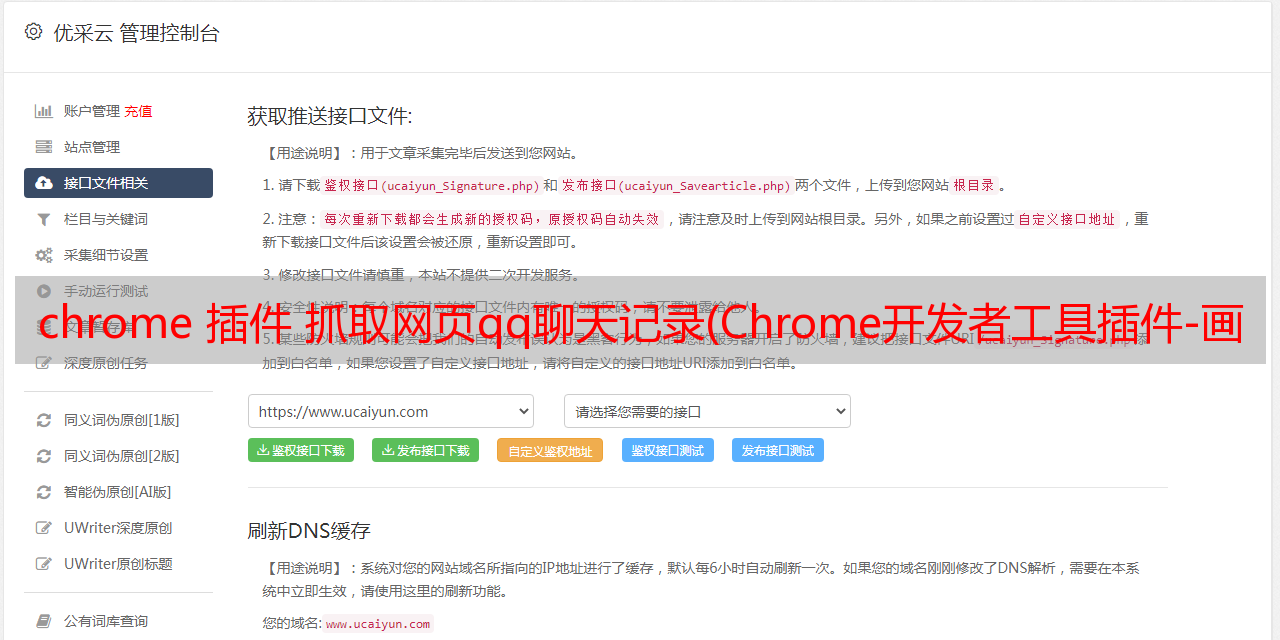
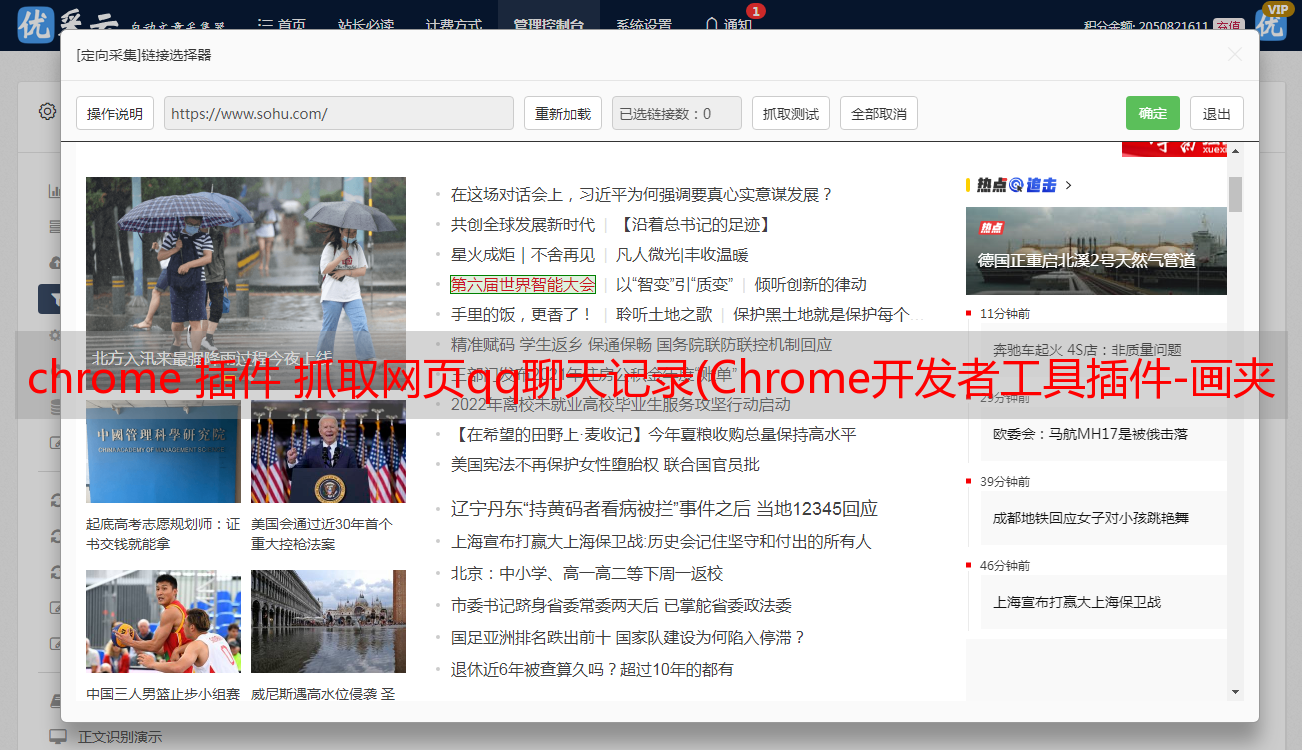
chrome 插件 抓取网页qq聊天记录(Chrome开发者工具插件-画夹插件网helper插件插件)
优采云 发布时间: 2021-11-30 11:14chrome 插件 抓取网页qq聊天记录(Chrome开发者工具插件-画夹插件网helper插件插件)
一:下载谷歌xpath插件,方便筛选
下载 Google Chrome xpath 插件,
链接:百度网盘-链接不存在
提取码:ar70
复制此内容后,打开百度网盘手机APP,更方便。
XPath Helper下载-Chrome开发者工具插件-图片文件夹插件网络
xpath helper 插件是一款免费的 chrome 爬虫网页解析工具。可以帮助用户解决获取xpath路径时无法正常定位等问题。这个插件主要可以帮助你在各种类型的网站上按shift键来帮助你提取和查询你想要查看的页面元素的代码。同时,您还可以编辑查询代码,编辑后的结果将立即出现在其旁边的结果框中。
二:命令行创建项目,创建爬虫
在终端下输入命令创建项目和爬虫
#创建工程
scrapy startproject Tencent
项目结构如下:
#创建一个爬虫,tencent是爬虫名,"tencent.com"是域名
scrapy genspider tencent "tencent.com"
创建成功后生成的新类:tencent.py
# -*- coding: utf-8 -*-
import scrapy
class TencentSpider(scrapy.Spider):
name = 'tencent'
allowed_domains = ['tencent.com']
start_urls = ['http://tencent.com/']
def parse(self, response):
pass
三:分析腾讯招聘网站,获取过滤规则
打开谷歌并输入网址:
F12 进入开发者模式并开始检查元素。
我们要抓取的信息包括:职位名称recruit_name、职位链接positionLink(*)、职位标签recruit_tips、职位描述recruit_text
打开xpath插件进行过滤,
//div//a//h4[@class="recruit-title"] 此规则过滤掉所有职位
//div//a//p[@class="recruit-tips"] 该命令过滤所有职位的标签信息
//div//a//p[@class="recruit-text"]/text() 抓取职位详情
难点:分析如何抓取下一页的信息。查了一下源码,发现下一页的href是直接找不到的,所以推测是通过js隐藏了网页的链接。(动态网页)
我们采取分析超链接跳转到下一页的方法,设置跳转的偏移量。这种方法有局限性。随时更改代码并设置最大页数。
四:编码
1、items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class TencentItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
positionName=scrapy.Field()
positionTips=scrapy.Field()
positionText=scrapy.Field()
2、tencent.py

