seo 百度 站长工具(垃圾外链带来的无用配额如何拒绝的)
优采云 发布时间: 2021-11-30 11:10seo 百度 站长工具(垃圾外链带来的无用配额如何拒绝的)
(1)查是否有黑链——从日志分析,百度蜘蛛爬取了网站哪些意想不到的页面,是否有黑链。(这个可能要先卖了,因为这是又是一个大项目,本期会提到一些话题)
(2)百度站长工具外链分析-检查是否有垃圾外链、黑链等,以及站内链接在哪,如何处理。(也涉及到这个问题)
(3)百度站长工具链接分析-三大死链(内链死链、链出死链、死链中链)、批量下载数据、合并数据、excel操作、逻辑分类、定位问题、处理(定位加工,材料不够,因为已经加工了很多,没有材料= =|||||)
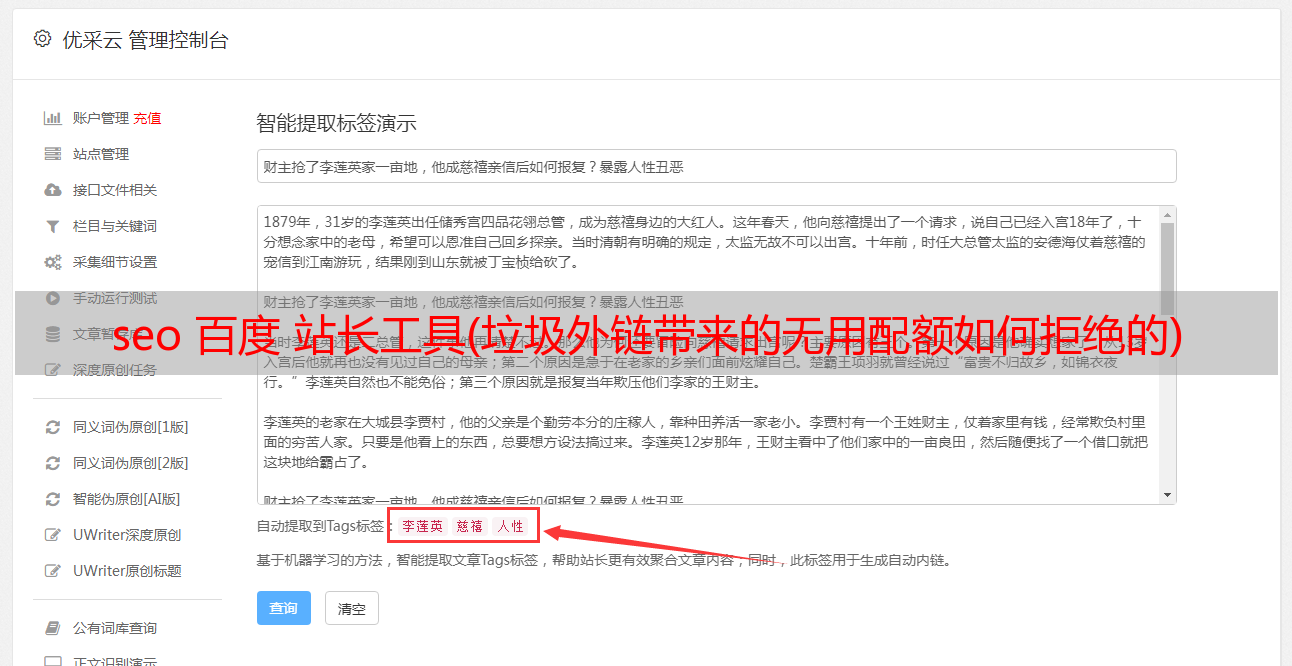
(4)通过分析这些数据得到的其他与SEO效果相关的信息(垃圾搜索引擎,垃圾外链导致的无用爬取,资源配额的浪费,如何拒绝。)
(5)如何用shell脚本自动定位百度蜘蛛爬取的死链接,进行审核,然后自动提交确定为死链接的网址。(本期话题太多,留着吧) (下一个话题)
(6)分析工具介绍(firefox设置、插件、excel、windows命令提示符批处理)
结合这篇文章,你或许能学会一些新的姿势,比如:
(1)在百度站长工具中批量下载表格数据(学习并灵活下载一些其他网站东西,只要你喜欢。比如5118什么的。5118的站长会不会玩我?)
(2)结合一些常用的文档,比如txt、csv等文本,方便数据分析处理。
(3)分析死链数据和定位问题的基本思路
本主题使用的主要工具:
(只是结合例子,如果有其他类似功能的工具,请根据自己的习惯使用)
[浏览器] 火狐浏览器,版本无所谓
[插件]:启动剪贴板
功能:一键打开剪贴板中已有的URL。(注意网址中标点符号只能使用英文数字,如果有中文可能无法识别)。快捷键:alt+shift+K(先复制一个或多个网址)
设置:打开选项设置,选择下载文件自动保存的位置(我这里选择的是桌面,也可以单独创建一个文件夹对批量下载的文件进行分类)
【表格处理】:Microsoft Office 2013 Excel
【文字处理】:记事本++
【批处理】:Windows自带命令提示符
这个问题用视频的解释过程:
来百度站长工具链接分析吧。我们看到有两个主要部分,死链接分析和外部链接分析。
一、 我们先来看看外链分析。
分析外链数据的主要目的是找出垃圾外链,主动屏蔽可能对网站造成不良影响的垃圾外链。最终目标:1、找到垃圾邮件外链的域名,进行防盗链处理(对于垃圾邮件域名,直接返回404状态码);2、 处理站点中可能有问题的页面。
在这里,我将重点说明这一点;第二点比较简单,我再粗略的解释一下。
1、 垃圾邮件域名定位。
图例:可以看到这是一张明显异常的趋势图
我们可以下载外部链接数据进行初步分析。
图例:下载的表单文件(csv 逗号分隔符)
但是这样的原创数据很难分析。所以,我们需要按照一定的逻辑来分析——也就是按照【链接网页的URL】来分类。
首先,我们可以快速浏览一下,做出直观的判断。这些页面大部分是什么类型的页面?
以我们的网站为例,外链数据分为两类,普通外链和垃圾外链。
垃圾外链分为站点搜索结果页(垃圾搜索词)和黑客植入的黑链接(已被处理为死链接)两种。
我们进行数据处理有两个目的:识别哪些是正常外链,哪些是垃圾外链,并根据垃圾外链的相关数据进行一些处理,以保护网站;并且需要垃圾链接指向的页面不会被搜索引擎抓取(浪费抓取资源配额)和收录/index(保证网站词库不被污染,不带图片到 网站 和 关键词 的负面影响)。
Step,过滤出网站的搜索结果页
图例:过滤数据,复制到新的工作表,删除原工作表中的过滤数据,对数据进行分类
还有几种类型的搜索链接格式,它们都以相同的方式处理。
然后对原创工作表中剩余的数据(空白行)进行去重,得到剩余的链接信息。
图例:对剩余数据执行简单的重复数据删除过程。
然后,我们需要过滤黑链。黑链的数据一般需要先从网站的日志中分析出来(这个很全面,为了保证效率,会需要使用shell脚本自动运行,但是涉及太多空间,我将在以后的主题中讨论它 解释)。
当然,你也可以将表格中【链接的网页网址】一栏进行排序,并在旁边进行分析(自己打开,黑客会使用一些特殊的方法来防止我们识别真正的被搜索引擎识别。垃圾邮件,常见的情况是用js跳转。这样我们通过浏览器访问的时候,看到的内容就完全不同了,搜索引擎抓取的时候就下载了垃圾邮件。)
这时候就需要使用firefox插件【No Script】来屏蔽网站上的js,看到类似搜索引擎的内容。
图例:在浏览器中阻止 JavaScript 插件
还有一种选择方法不是很可靠。在搜索引擎中搜索:【站点:域名*敏*感*词*】关键词,把不符合网站期望的关键词去搜索,可以得到很多链接。(这里需要用到一些方法,批量导出所有链接,后面的话题我会继续讲解)
我只能省略筛选过程,大家可以结合视频看一下。
图例:过滤后的网站黑链
我们之所以要这么努力地找出垃圾链接,是为了记录这些垃圾链接的域名,防止这些垃圾域名被黑客重用,制作新的垃圾链接,从而拒绝这些垃圾链接。时间。外部链接,当百度蜘蛛从外部垃圾链接访问我们网站上的内容时,无法获取任何信息(即返回404状态码,被识别为死链接)。随着时间的推移,这些垃圾域名的权重会越来越低(因为死链接被派生出来,影响了搜索引擎的正常抓取工作),这样我们既保护了自己,也惩罚了敌人。
具体方法是找出垃圾页面——从搜索结果页面和黑链的两张页面,将外链页面整合到一起。如sheet3所示。
图例:合并垃圾外链页面
接下来的处理将使用一个小工具来快速获取这些链接的主域名。
图例:复制左边红框的链接,点击本地提取,会出现在右边的红框中
这样我们就得到了这些垃圾外链页面的主域名,我们只需要在我们的服务器上配置防盗链,并禁止refer(源)访问这些域名(返回404http状态码)。
2、处理来自本站的搜索结果页面(黑链处理在下个话题中保留,因为大量的linux shell脚本组合在一起):
对于权重较高的网站的站内搜索,一定要注意反垃圾邮件(anti-spam)。如果不采取预防措施,一旦被黑客利用,可能会导致大量搜索页面被百度抓取。黑客利用高权重网站的资源,快速做好黄赌毒行业的关键词排名。但这对我们来说是噩梦般的打击网站。如果不处理,可能会导致以下问题:浪费大量蜘蛛爬取配额去爬取垃圾页面;垃圾页面被搜索引擎收录污染,网站词库被黑客污染,使得网站的行业词和品牌词排名不理想;它对网站...等的形象造成损失。
在执行这种反垃圾邮件策略时,我们需要注意四个方面:站点上的用户能否正常使用;不允许搜索引擎抓取此类页面;拒绝访问垃圾邮件外部链接;垃圾邮件不应出现在页面关键词 上。
既然有了明确的目标,相应的应对方案也出来了,那就是:
A 限制来源,拒绝所有来自非网站来源的搜索
B页TKD等关键位置,请勿调用搜索词
C 指定敏感词过滤规则,将敏感词全部替换为星号*(有一定的技术开发要求)
D 在robots.txt 中声明不允许爬行
E 在页面源码的head部分添加meta robots信息,说明页面不允许索引(noindex)
以上处理可以解决大部分网站上容易出现搜索页面的问题(不限于这种类型的页面,甚至其他页面,只要你不想让搜索引擎对其进行抓取和索引)。
二、 再来看看死链分析。
死链接,站长工具的死链接提交工具的帮助文档里有详细的说明,我只需要补充一些。
一般有几种类型的死链接:内部死链接和外部死链接。
内部死链就是我们网站上出现的死链。由于种种原因,当百度蜘蛛抓取链接时无法获取到内容时,就被识别出来了。大多数情况下,对于我们来说,这个死链是可以通过某种方式避免的,所以是可控的。同时,由于死链接页面的链接都是我们网站上的页面,而且死链接页面都是链接的,对搜索引擎非常不友好,所以如果不处理时间,很可能会引起搜索引擎的注意。无法顺利爬取网站上有价值的页面,间接导致“部分掉电”(爬取某些页面的周期越来越长,快照更新慢,排名不升等) .
内部死链问题比较严重,首先要处理内部死链。
并且我们可以在百度站长工具中慢速获取死链数据,按照一定的逻辑方式进行排序和划分,定位问题所在。接下来,我将解释死链接数据分析。
通过在页面上预览死链接信息,谁都知道怎么做,就不用我过多解释了。至于死链问题,不用每天下载表格进行分析。相反,你只需要每天查看数据,看看是否有突然的死链,找出原因并进行处理(一般它发生的规模较大,更容易被发现,但也必要。紧急处理);其次,我们需要定期对死链接进行更彻底的数据分析,看看是否有我们平时不注意的死链接。, 可能会引起大问题)。
图例:一般突然出现的大量死链接很容易被检测到,最好能确定原因
图例:这是早期定位的问题。虽然提交了解决方案,但被程序员无视,不久就突然爆发了。所以,即使是小问题也要引起足够的重视(因为处理的及时,所以没有出现太严重的问题)
下面简单说一下在百度站长工具中批量下载死链数据,合并数据统一处理。
链内死链接(子域 A 指向子域 A)和出站死链接(子域 A 指向子域 BCD...)通常更容易分析。让我们重点关注入站死链接(子域 BCD...)指向子域 A)做一些批处理。
图例:可以下载数据,格式为csv(逗号分隔符),可以方便的用excel进行处理
; 并且下面有官方帮助文档。
在这里,您可以尝试点击【下载数据】,Firefox 会自动将文件下载到您设置的位置。
这里告诉你一个小技巧,你可以点击下载列表中对应的文件,复制下载链接,粘贴出来。
:///&download=1&type=3&day=2016-02-30&f=dead_link&key=
相信帅哥已经看过了,site=是指定你的网站域名,day=2016-02-30是指定你需要的日期。type=3是指定要下载的数据【链接到死链接】,type=2是链接出死链接,type=1是内链死链接。其他参数不需要了解太多。
脑子大的朋友肯定会想,如果我对日期参数做一些处理,可以直接批量下载这些文件吗?是的,没关系。这里就需要利用excel的强大功能了。
首先手动制作两行URL,然后选择,从右下角左键单击并按住,下拉,您会发现excel已经自动为您完成了URL。很方便。
松开左键,得到想要的结果
然后,你可以复制这些网址,然后进入Firefox,使用我们之前安装的Launch Clipboard插件,使用它的快捷键alt + shift +K批量打开上图中的链接,然后我们的Firefox浏览器这些文件会自动下载并存储到我们指定的位置。
来,我们来看看收获的结果:
好像没问题?但是,我应该一个一个打开这么多表格吗?
当然不是。让我们来看看某种形式的样子。你看见了吗?这里是时间记录器。
换句话说,如果我们能找到一种方法来合并这些文件,那么也有一种方法来区分日期。
好吧,就去做吧。
(1)打开你的命令提示符:Windows + R,输入cmd,回车
(2)在命令提示符下输入cd并输入空格,然后到csv文件的保存位置,将整个文件夹拖到命令提示符下自动补全路径。
如果不进入cd空间会报错,如下图。(cd 表示跳转目录到指定目录)
成功后就可以将所有的csv文件合并到一起,输入命令:
复制 *.csv..ok.csv
这意味着所有后缀为 csv 的文件都被复制出来并输出到上级目录中的 ok.csv 文件中。
这样就完成了合并。
我们打开ok.csv看看?然后我们就可以进行简单的重复数据删除处理了。
图例:经过简单的去重后,我们还是可以大致浏览的。
我们发现在死链的前链中,有很多页面来自不同域名的相似目录。我们不妨分别保存这些页面。
图例:过滤掉所有子域下所有收录小曲目录的页面
然后我们发现还有一些页面收录/。这些页面一般都是通过推送数据来抓取的,所以暂时分类放在一边。
图例:百度的爬取数据
在剩余的数据中,仍然存在外部死链接,外部死链接也收录一些垃圾链接。我们需要找出这些垃圾邮件链接。
图例:按死链接排序
垃圾死链接也被归为一个单独的类别,剩下的就是真正的外部死链接。
图例:是时候检查结果了。
我们按照一定的逻辑关系将数据分为四类,分别是【外部死链接】【垃圾链接】【百度】【子域名(也属于内部死链接)】
我们需要关注的是出现在[子域]中的死链接。因为子域也是我们网站的一部分,所以这些页面存在死链接,势必对这些页面的SEO效果不利,需要尽快查明原因。
与技术部沟通后,确认出现此类问题的原因主要是我们的网站服务器之间数据同步不成功,或者服务器之间的连接意外断开。这类问题暂时难以避免,所以技术人员只能将因为这种情况出现的404(永久不可访问)状态码改回503(暂时不可访问)状态码。
【百度】死链接的原因和上面一样。只是蜘蛛的爬取通道来自于主动推送方式。返回503状态码后,情况有所好转。
【垃圾链接】,我在外链分析中已经做了一定程度的说明,大家可以参考。
【外部死链接】,这个不用太关注。受死链接影响的不是我们的网站,而是导出死链接的网站。但有时你分析一下,总能发现一些有趣的现象。
比如我现在看到的数据的共性是死链不完整,要么中间省略了点,要么强行截断了尾部。我们打开死链前端链接,发现死链链接在页面上是作为一个清晰的链接(unnchored text)出现的。死链前链接的大部分页面都类似于搜索引擎结果页面,这些结果页面上的锚链接是由nofollow控制的。
图注:这些都是垃圾邮件搜索引擎,目的是抓取其他网站信息供自己使用,制造垃圾邮件站群
可见,大部分【垃圾链接】和【外链死链接】还是带有恶意的。这时候我们可能需要考虑使用反爬虫策略来禁止一些垃圾搜索引擎随意抓取我们网站。(关于反爬虫策略的话题,打算以后试试)
嗯,这个问题的内容差不多就是这样,我们总结一下。
(1) 分析链接数据的目的:保证搜索引擎对网站的正常抓取和索引;防止因恶意使用而造成的损失。
(2) 分析链接数据的手段:一些工具,加上简单的逻辑。
(3)养成良好的工作习惯和意识:每天密切关注数据,仔细分析数据,可控操作这些环节。
更多麦贝商城产品介绍:百度空间推广软件网易企业邮箱价格视听娱乐网站源码

