php抓取网页指定内容(关于本项目复用性和二次开发性很好的代码注释)
优采云 发布时间: 2021-11-16 08:02php抓取网页指定内容(关于本项目复用性和二次开发性很好的代码注释)
关于这个项目

为什么选择这个项目
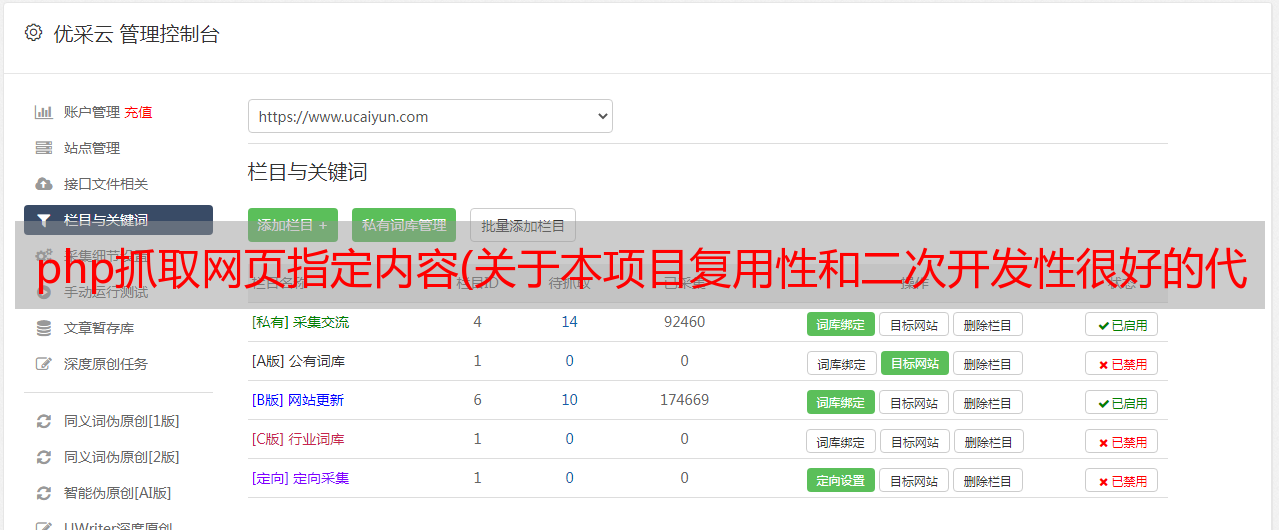
复用性和二次开发都很好。项目很多部分都有详细的代码注释,方便阅读。即使这个项目不能完全满足你对微博数据采集和分析的需求,你也可以在这个项目的基础上做二次开发。项目已经做了微博爬取和各种模板的分析。很多工作。由于这个项目与我的实际工作有关(代码不是我工作中使用的代码),我可以放心,它会长期更新。它已经迭代了一年多。丰富的文档支持:请点击wiki查看所有文档。如果文档仍然不能解决您的问题,请提出问题。维护者看到后会积极回答。也可以添加QQ群(群号:499500161,密码:微博爬虫,请注意群信息,否则将被视为广告处理)进行交流。配置和使用

使用前请务必仔细阅读项目配置和项目使用
配置
建议新手新手先查看演示视频(链接:密码:ypn5)
项目相关配置
其实上面已经介绍了完整项目的配置过程。如果熟悉docker,也可以使用基于docker的方式进行部署。如果你有使用docker的经验,我大概就不用多说了,关注就好了。构建镜像时需要在项目的根目录下,因为在构建镜像的过程中会复制整个WeiboSpider项目。编码,除了安装的灵活性外,没有其他方法可以找到它。图像构建语句可以是
docker build -f WeiboSpider/Dockerfile -t resolvewang/weibospider:v1.0.
镜像构建完成后,容器默认运行,接受所有任务路由。如果只接收到一部分,可以直接覆盖CMD命令。比如我只想执行登录任务,那么
docker run --name resolvewang/weibospider:v1.0 celery -A tasks.workers -Q login_queue worker -l info -c 1
比如通过docker启动定时器
docker run --name spiderbeater resolvewang/weibospider:v1.0 celery beat -A tasks.workers -l info
用
基本用法:请先将基本数据添加到数据库中,然后按照启动每个节点worker->运行login_first.py->启动定时任务或其他任务的顺序进行,下面是详细说明
其他
常见问题
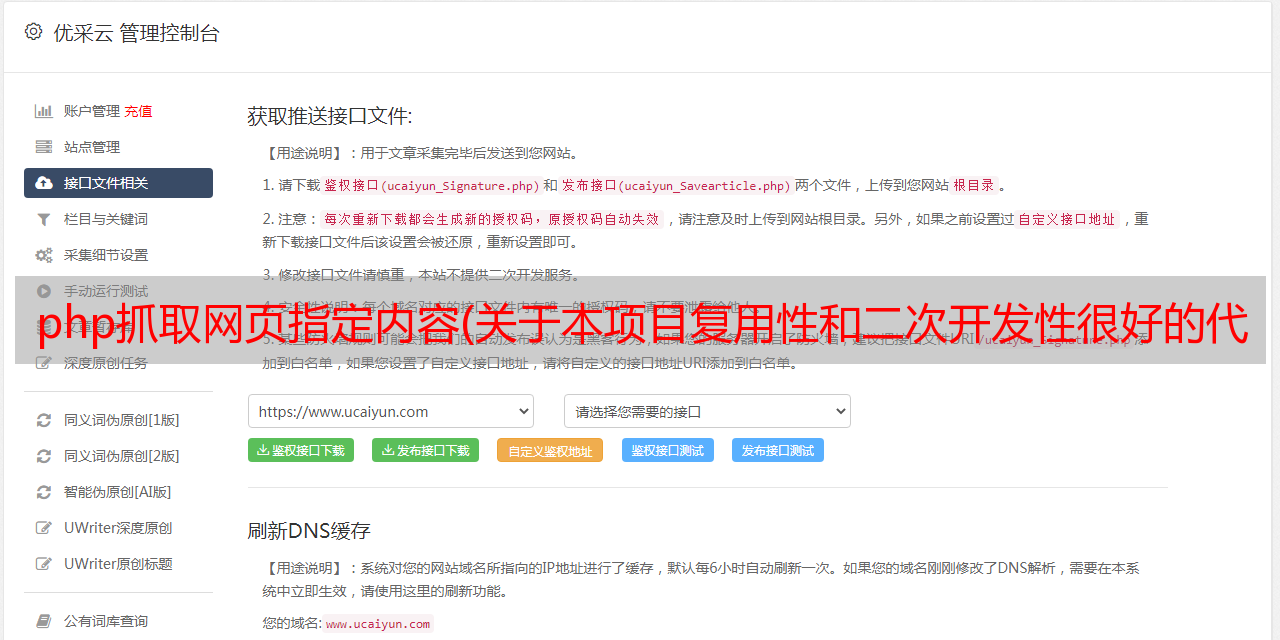
1.Q:项目部署好复杂。我没有多台机器。我可以在一台机器上运行它吗?
答:它可以在单个节点上运行。Celery 是去中心化的。如果你因为硬件限制只有一台机器,也可以直接按照本文档的说明和项目中的配置文档运行项目。关于项目使用的问题可以在issue中提出。
2.关于redis:为什么我给redis设置了密码后,把redis设置为守护进程,却不起作用?
答:其实这个问题和项目关系不大。. . 不过考虑到有同学对redis不熟悉,我澄清一下,如果在linux上使用redis,我们修改redis.conf文件后,在启动redis的时候还需要指定redis.conf文件,然后再启动。之前,最好在环境变量中加入redis-server。比如我的redis.conf放在/etc/redis,那么我可以先切换到/etc/redis目录,然后通过redis-server redis.conf启动redis服务器,或者直接redis-server /etc /redis /redis.conf 启动,前提是redis-server文件需要在环境变量中。另外要注意的是,如果是centos,redis3.2.7在make&&make install阶段可能会报错,
3.这个项目在模拟登录爬取过程中验证码怎么处理?
答:本项目会在模拟登录阶段判断账号是否需要验证码。对于需要验证码的账户,使用编码平台识别验证码。出现的验证码,目前的流程是从数据库和redis中删除账户对应的信息,因为登录后被屏蔽后需要一些时间来测试,在某些情况下会验证手机,而在某些情况下它只是识别验证码,这需要进一步验证。
另外,我们应该尽量避免使用验证码。例如,在登录帐户时尽可能多地尝试登录。还有一点就是考验微博的容忍度。采集 小于它的阈值就不容易被屏蔽(但是很慢),毕竟按照规则被屏蔽的风险要小得多。如果有解决过验证码问题的图形和图像识别专家,欢迎PR帮助更多人。
4.这个项目可以在windows上执行吗?
答:worker节点可以在window上执行,但是beat节点(即定时任务)不能执行。如果想混用windows和linux,必须将celery版本降级到3.1.25,并将beat节点部署到linux服务器。
5.这个项目一天能抓取多少数据?
答:如果使用极速模式,3台机器每天可以抓取数百万条用户信息,可以抓取几千万条微博信息(如果使用搜索抓取相关微博,这个数量不会达到,因为搜索接口很有限。很严格),它的代价就是账号难免会被封。建议在线购买小账号进行爬取。如果采用普通模式,那么三台机器每天可以抓取大约几万条用户信息,账户相对安全。另外还有一点,微博搜索的限制比较严格,速度可能比抓取用户信息和用户主页微博慢。这可能会在稍后针对具有不同需求的用户进行处理。
6.为什么这个项目搜索抓取的数据和手动搜索的数据量不一致?
答:不一致主要是因为搜索是高级搜索。默认只搜索原创微博,用户手动搜索所有搜索到的微博,包括转发的,所以数据量会有差异。获取所有微博,然后修改搜索模块的url和home模块中home_url的值。
7.可以为这个项目做一个web监控管理页面吗?
答:其实这个需求不是必须的,flower已经提供了类似的功能。使用flower,我们可以监控每个节点的健康状况并查看执行任务的状态
其他说明
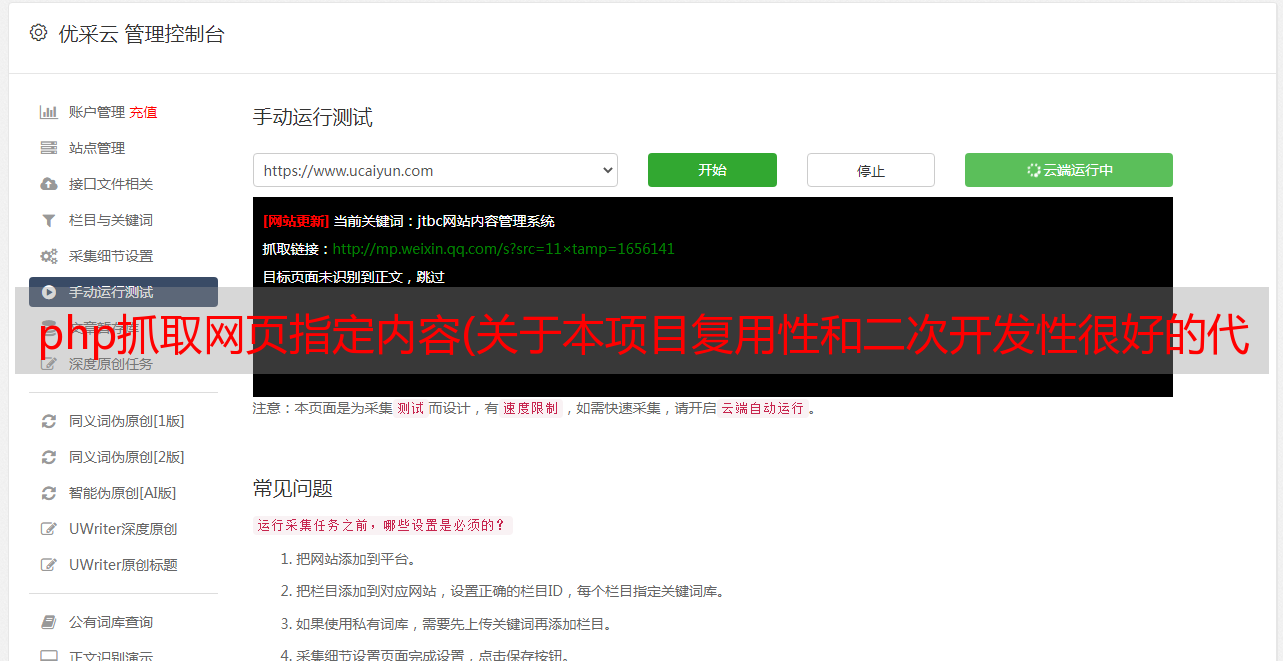
去做

反爬虫相关
其他
如何贡献
点击查看贡献者名单
赞助这个项目
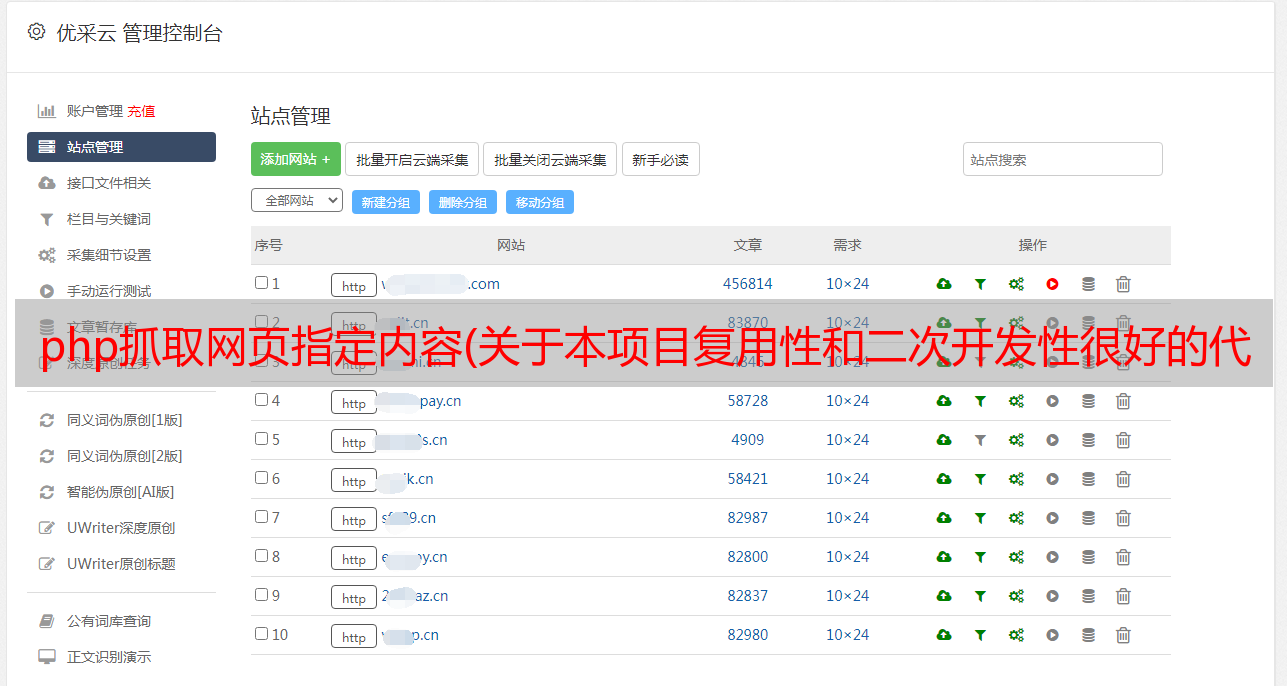
如果这个项目确实解决了你的刚性需求,或者对你有更大的启发,不妨邀请作者喝杯咖啡或者买一本新书。
谢谢

最后祝大家使用愉快,欢迎投诉!

