抓取动态网页(ajax和Chrome的内核,性能你懂的,在真实场景中还是以它为主)
优采云 发布时间: 2021-11-14 16:13抓取动态网页(ajax和Chrome的内核,性能你懂的,在真实场景中还是以它为主)
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,跳过了js加载部分,也就是网页爬虫抓取的不完整,不完整。您可以在下面看到博客花园主页。从首页加载可以看出,页面渲染完后,还会有5个
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,这就是其中之一
跳过js加载部分,表示爬虫爬取的网页不完整,不完整。您可以在下方查看博客园主页
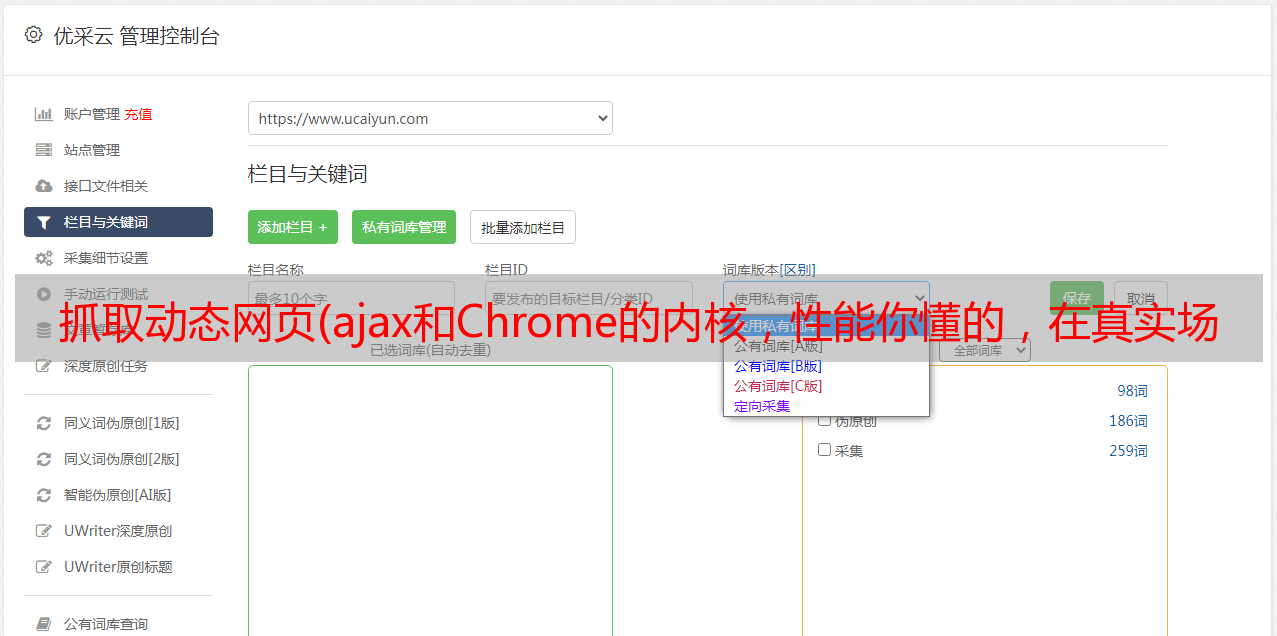
从首页的加载可以看出,页面渲染后,会有5个ajax异步请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候想要获取就必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎具有三大支柱。
Trident:是IE核心,WebBrowser就是基于这个核心,但是加载性比较差。
Gecko:FF的核心,性能优于Trident。
WebKit:Safari 和 Chrome 的核心。性能如你所知,在实景中依然是中流砥柱。
好吧,为了简单方便,这里我们用WebBrowser来玩玩。使用WebBrowser时,要注意以下几点:
第一:因为WebBrowser是System.Windows.Forms中的winform控件,所以需要设置STAThread标签。
第二:Winform 是事件驱动的,Console 不响应事件。所有事件都在 windows 消息队列中等待执行。为防止程序假死,
我们需要调用DoEvents方法来转移控制权,让操作系统执行其他事件。
第三:WebBrowser中的内容,我们需要使用DomDocument查看,而不是DocumentText。
判断一个动态网页是否已经加载,通常有两种方法:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们需要在这里
记录计数值
.
1 使用系统; 2 使用 System.采集s.Generic; 3 使用 System.Linq; 4 使用 System.Text; 5 使用 System.Windows.Forms; 6 使用 System.Threading; 7 使用System.IO; ConsoleApplication210 {Program12 {hitCount = 0;14 15 [STAThread]Main(string[] args)17 {;19 20WebBrowser browser = new WebBrowser();21 22browser.ScriptErrorsSuppressed = true;23 24browser.Navigating += (sender, e) =>25 {26hitCount++;27 };28 29browser.DocumentCompleted += (sender, e) =>30 {31hitCount++;32 };33 34 browser.Navigate(url);(browser.ReadyState != WebBrowserReadyState.Complete)37 { 38 申请。 DoEvents();39 }(hitCount

