网页数据抓取怎么写(1.-blog-article-1.博客信息详解(图) )
优采云 发布时间: 2021-11-11 15:05网页数据抓取怎么写(1.-blog-article-1.博客信息详解(图)
)
1. 设计理念
因为博客有分页功能,如果要获取所有的博客信息,首先要算出总共有多少页。抓取当前页面后,跳转到下一页抓取新的博客信息;
获取页数有两种方式:
1. 通过爬取分页值

但是这种方法的识别度在获取类信息方面是不够的,类会在选中状态下发生变化。
2. 获取博客总数/每页条目数=页数
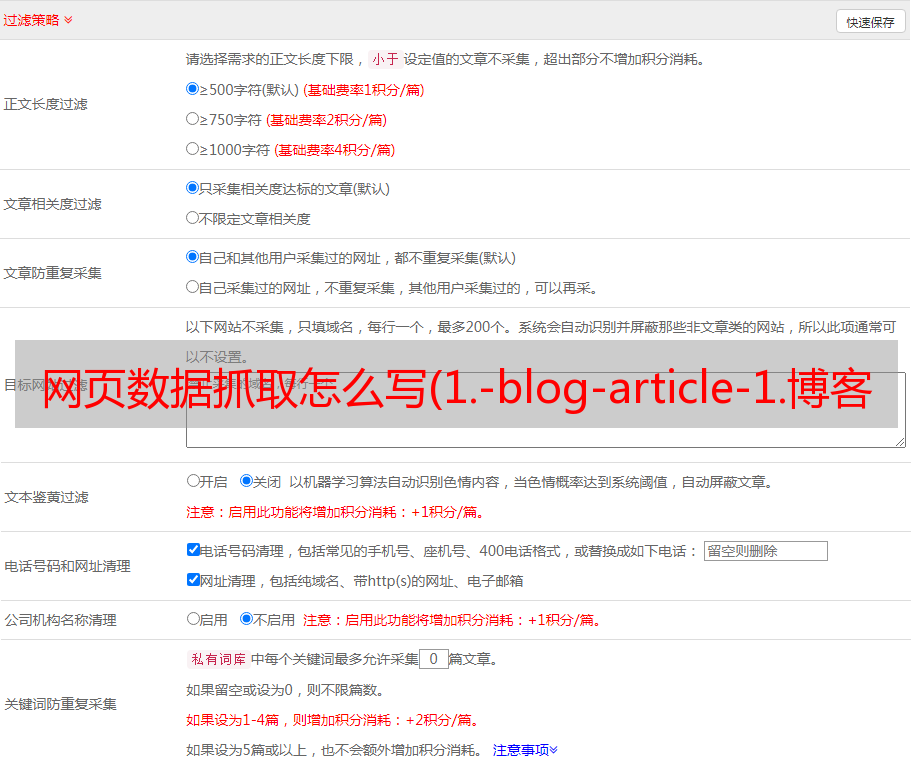
这样,只识别一条备忘录内容就足够了,通过正则化得到该值就可以得到博客总数。但是,当系统更改每页的项目数时,分页结果可能会不准确。当前的 csdn 是每页 40 项。如果变成20,就会出现数据差异。
获取到页数后,需要遍历博客每个页面的地址,获取不同页面的博客信息
目前页面地址只是数值代表变化的地址栏,所以可以直接根据页面数遍历拼接地址来获取博客内容
完整的代码会在最后贴出来,下面只是获取页数的部分代码:
<p> public static List allArtitcle()throws IOException{
Connection conn = Jsoup.connect(URL)
.userAgent("Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:50.0) Gecko/20100101 Firefox/50.0")
.timeout(5000)
.method(Connection.Method.GET);
Document doc = conn.get();
Element body = doc.body();
//获取总页数
// 获取博客总数的代码
Element articleListDiv = body.getElementById("container-header-blog");
// 获取span标签的内容
String totalPageStr = articleListDiv.select("span").text();
// 正则取数字
String regEx="[^0-9]";
Pattern p = Pattern.compile(regEx);
Matcher m = p.matcher(totalPageStr);
int totalPage = (int) Math.ceil(Double.valueOf(m.replaceAll("").trim())/40L);
int pageNow = 1; // 初始页数
// 遍历传递页数进行下一个方法的地址拼接
List articleList = new ArrayList();
for(pageNow = 1; pageNow

