网页爬虫抓取百度图片(爬取某个前端知识分析之不会网站页面的定位与布局 )
优采云 发布时间: 2021-11-08 17:06网页爬虫抓取百度图片(爬取某个前端知识分析之不会网站页面的定位与布局
)
介绍
本案例只是为了巩固Xpath语法的使用,不会涉及到爬虫知识太深
分析:
一般我们在爬取某个网站页面时,有以下几个步骤:
1、获取爬取目标地址
2、明确需求,即要知道网页中获取哪些数据
3、 明确目标后,通过相应的解析语法(Xpath)分析网页的结构,得到想要的数据
4、写代码实现
1、获取爬取目标地址
以*敏*感*词*为例:
程序员吧-*敏*感*词*--程序员之家,全球最大的程序员中文*敏*感*词*。--Programmer(英文程序员)是从事程序开发和维护的专业人士。一般来说,程序员分为程序员和程序员,但两者的界限不是很清楚。
2、明确需求
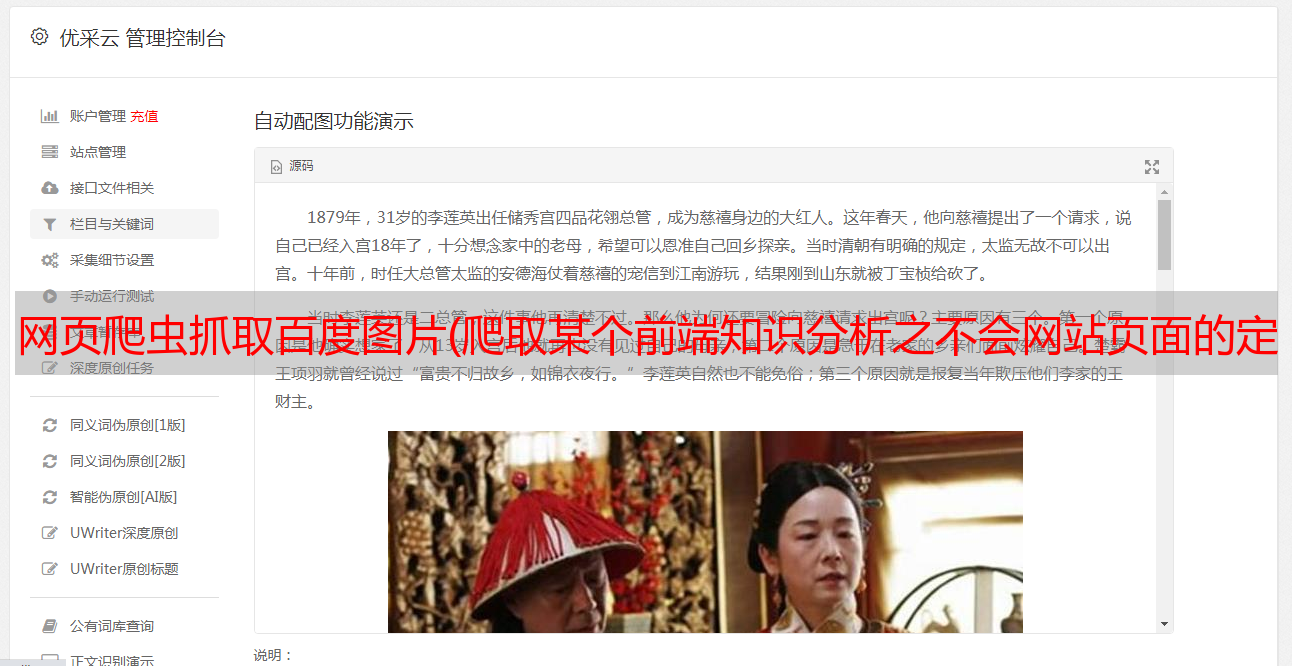
获取贴吧的每个帖子的标题,如下图:
3、使用Xpath解析网页结构获取想要的数据1、通过浏览器工具快速定位到网页中需要获取的数据的标签位置
1、在网页上右键,点击检查
2、 然后弹出
3、点击左上角的箭头标志
4、 鼠标悬停在网页的数据上,左边的显示会自动跳转到对应的标签,既然是获取文章的标题,那么我们将鼠标悬停在一个的标题上邮政
定位已定位,但这就是我们想要的吗?显然不是,因为这只是定位一个帖子,显然不符合我们的需求。我们想要得到整个网页(注意这是一个网页,不是网站)所有帖子的标题。
其实一个的定位已经是一半了,因为其他帖子的tag结构和属性都是一样的,不会有什么区别,做过前端的兄弟都知道。那么问题来了,既然是一样的,为什么不直接使用呢?这又是一个前端知识。其实网站的大部分布局就像很多拼图,所以这部分帖子是一体的。在拼图中,我们现在要找到这块拼图。从Xpath语法的角度,我们通过路径搜索和属性值定位来定位标签。如果直接用label属性值来定位,就可以了,因为一下子就定位到了。显然不可保,可能会有更多不需要的数据。
想法:
1、 先搜索路径,找到存放所有帖子的父标签
2、由于帖子的标签结构和属性值都是一样的,随便找一篇帖子分析一下就行了。后面写个例子看看效果
2.使用Xpath-helper插件验证Xapth语法是否正确获取数据
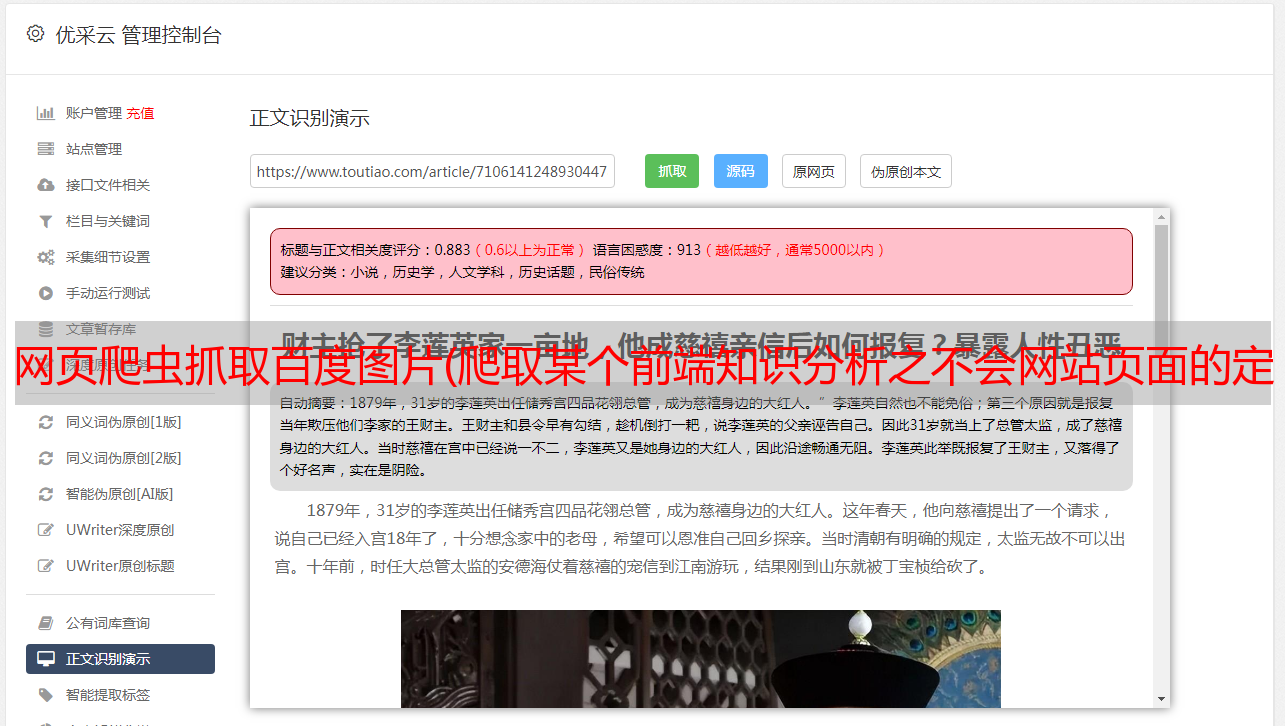
知道了数据的位置,我们就开始写Xpath语法来定位数据,那我们怎么知道我们写的语法是否正确,这个就用我们的Xpath-helper插件来验证。
1、 首先,我们观察一下贴吧中一个网页上有多少帖子
不收录广告,一共50条,所以只要我们写好语法就可以得到50条帖子的数据是正确的
2、使用插件,点击右上角拼图
3、点击Xpath-helper插件
4、 弹出两个框
5、 左边的框是输入我们的Xapth语法,右边是根据语法自动获取的数据
编写 Xpath 语法
1、只使用属性值定位(不推荐)
使用鼠标定位其中一个帖子
提供日千万预算,长期高价收wap量,正规无感广告,寻站长合作共
语法:
//a[@class="j_th_tit"]
影响:
可以得到五十条数据,语法正确,为什么不推荐呢,比如我们不使用class属性而是使用rel属性
//a[@rel="noreferrer"]
影响:
230条数据,明显错误。
2、结合路径搜索和属性搜索(推荐)
首先,您需要知道帖子拼图的标签。您只需要收录帖子这部分内容的标签即可。
从图中我们可以知道帖子的信息在li标签中,我们想要的数据肯定在li标签中,解析li标签
我们可以根据a标签逐层查找。有一个问题,就是会出现同一个标签,而且两个级别相同,那么如何区分,如下图:
可以看出我们想要的内容在第二个div标签下。两者如何区分,通过属性值很容易区分。
语法:
//ul[@id="thread_list"]/li/div/div[@class="col2_right j_threadlist_li_right "]/div/div/a
影响:
语法的写法是自己决定的,只要得到正确的数据即可
3、获取数据
我们上面所做的只是定位数据所在的标签,并没有真正获取到值,根据标签中数据的形式获取
提供日千万预算,长期高价收wap量,正规无感广告,寻站长合作共
可以看到a标签的title属性的值就是我们想要的数据,中间也有我们想要的值,所以有两种写法,根据自己的喜好
语法:
写一:
//ul[@id="thread_list"]/li/div/div[@class="col2_right j_threadlist_li_right "]/div/div/a/text()
影响:
写作二:
//ul[@id="thread_list"]/li/div/div[@class="col2_right j_threadlist_li_right "]/div/div/a/@title
影响:
4、写代码实现
代码:
import requests
import time
from lxml import etree
def getHTMLContent(url):
# 伪装用户代理,防反爬
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'
}
# 向url发送get请求
respone = requests.get(url,headers = header)
# 将返回的二进制流文件转化成文本文件
content = respone.text
# 减少一些无用的标签的干扰,这个标签在html语言是属于注释标签
content = content.replace('', '')
# 将返回的html文本文件转化成xpath能解析的对象
tree = etree.HTML(content)
# 根据xpath语法获取内容
titles = tree.xpath('//ul[@id="thread_list"]/li/div/div[@class="col2_right j_threadlist_li_right "]/div/div/a/text()')
# 循环打印结果
for title in titles:
print(title)
if __name__ =="__main__":
url = "https://tieba.baidu.com/f?kw=%E7%A8%8B%E5%BA%8F%E5%91%98&ie=utf-8&pn=50"
getHTMLContent(url)
结果: