网页抓取数据百度百科(【Python基础爬虫篇】本篇讲解一个比较简单的Python爬虫)
优采云 发布时间: 2021-11-03 06:07网页抓取数据百度百科(【Python基础爬虫篇】本篇讲解一个比较简单的Python爬虫)
[基础爬虫文章]
本文介绍了一个相对简单的 Python 爬虫。
这个爬虫虽然简单,但是五脏俱全。基础爬虫有大爬虫的模块,但大爬虫做的更全面、更多样化。
1. 实现的功能:该爬虫实现的功能是抓取百度百科中的词条信息。爬取结果见6。
2.背景知识:(1).Python 语法;(2).BeautifulSoup;(3).HTML 知识;
学习Python基础语法请参考:推荐《Python编程-从入门到实践》,或廖雪峰的Python博客。
BeautifulSoup的主要语法请参考:BeautifulSoup的主要知识点
3.基本爬虫框架及运行流程:
基本爬虫包括五个模块,分别是爬虫调度器、URL管理器、HTML下载器、HTML解析器和数据存储。
功能分析如下:
(1)。爬虫调度器主要负责协调其他四个模块的协调;
(2)。URL管理器负责管理URL链接,维护已爬取的URL集合和未爬取的URL集合,并提供获取新URL链接的接口;
(3).HTML下载器用于从URL管理器获取未抓取的URL链接并下载HTML网页;
(4)。HTML解析器用于从HTML下载器获取下载的HTML网页,解析新的URL链接到URL管理器,将有效数据解析到数据存储。
(5)。数据存储用于将HTML解析器解析的数据以文件或数据库的形式进行解析。
文件组织目录:
__init__.py 的内容是空的,它的作用只是把这个包变成一个模块,身份已经改变了。
1.网址管理器
链接去重是Python爬虫开发中的必备技能。主要有以下三种解决方案:1)。内存重复数据删除; 2)。关系型数据库重复数据删除; 3)。缓存数据库重复数据删除;在这个基础爬虫中,由于数据量比较小,我使用了Python中set的内存去重方法。
# url管理器
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def has_new_url(self):
'''
判断是否有未爬取的URL
:return:
'''
return self.new_url_size() != 0
def get_new_url(self):
'''
获取一个未爬取的URL
:return:
'''
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
def add_new_url(self, url):
'''
将新的URL添加到未爬取的URL集合中
:param url: 单个url
:return:
'''
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
'''
将新的URL添加到未爬取的URL集合中
:param urls: urls:url集合
:return:
'''
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def new_url_size(self):
'''
获取未爬取的URL集合的大小
:return:
'''
return len(self.new_urls)
def old_url_size(self):
'''
获取已经爬取的URL集合的大小
:return:
'''
return len(self.old_urls)
2.HTML 下载器
HTML 下载器用于下载网页。这时候需要注意网页的编码,确保下载的网页没有乱码。下载器使用Requests模块,比urllib强大很多。
import requests
import chardet
class HtmlDownloader(object):
def download(self, url):
if url is None:
return None
user_agent = 'Mozilla/4.0 (compatible); MSIE 5.5; Windows NT'
headers = {'User-Agent': user_agent}
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = chardet.detect(response.content)['encoding']
return response.text
else:
print('网页打开失败!')
return None
3.HTML 解析器
HTML 解析器使用 BeautifulSoup 进行 HTML 解析。需要解析的部分主要分为提取相关条目页面的URL和提取当前条目的标题和摘要信息。
4.数据存储
数据存储主要包括两种方法:store_data(data)用于将解析后的数据存储在内存中,output_html()用于将存储的数据输出为指定的文件格式(自定义)。
import codecs
class DataOutput(object):
def __init__(self):
self.datas = []
def store_data(self, data):
if data is None:
return
self.datas.append(data)
def output_html(self):
fout = codecs.open('baike.html', 'a', encoding='utf-8')
fout.write('')
fout.write('')
fout.write('')
fout.write('')
for data in self.datas:
fout.write('')
fout.write('%s'%data['url'])
fout.write('%s'%data['title'])
fout.write('%s'%data['summary'])
fout.write('')
self.datas.remove(data)
fout.write('')
fout.write('')
fout.write('')
fout.close()
5.爬虫调度器
爬虫调度器用于协调和管理这些模块。
# encoding:utf-8
from The_Basic_Spider.DataOutput import DataOutput
from The_Basic_Spider.HtmlDownloader import HtmlDownloader
from The_Basic_Spider.HtmlParser import HtmlParser
from The_Basic_Spider.URLManager import UrlManager
class SpiderMan(object):
def __init__(self):
self.manager = UrlManager()
self.downloader = HtmlDownloader()
self.parser = HtmlParser()
self.output = DataOutput()
def crawl(self, root_url):
# 添加入口URL
self.manager.add_new_url(root_url)
# 判断url管理器中是否有新的url,同时判断抓取了多少个url
while(self.manager.has_new_url() and self.manager.old_url_size() < 100):
try:
# 从URL管理器中获取新的url
new_url = self.manager.get_new_url()
print(new_url)
# HTML下载器下载网页
html = self.downloader.download(new_url)
# HTML解析器抽取网页数据
new_urls, data = self.parser.parser(new_url, html)
print(new_urls, data)
# 将抽取的url添加到URL管理器中
self.manager.add_new_urls(new_urls)
# 数据存储器存储文件
self.output.store_data(data)
print('已经抓取了%s个链接' % self.manager.old_url_size())
except Exception:
print('crawl failed')
# 数据存储器将文件输出成指定格式
self.output.output_html()
if __name__ == '__main__':
spider_man = SpiderMan()
spider_man.crawl('http://baike.baidu.com/view/284853.htm')
然后就可以抓取100条百度百科词条了~抓取到的信息会保存在baike.html中。
6.爬取结果(baike.html)
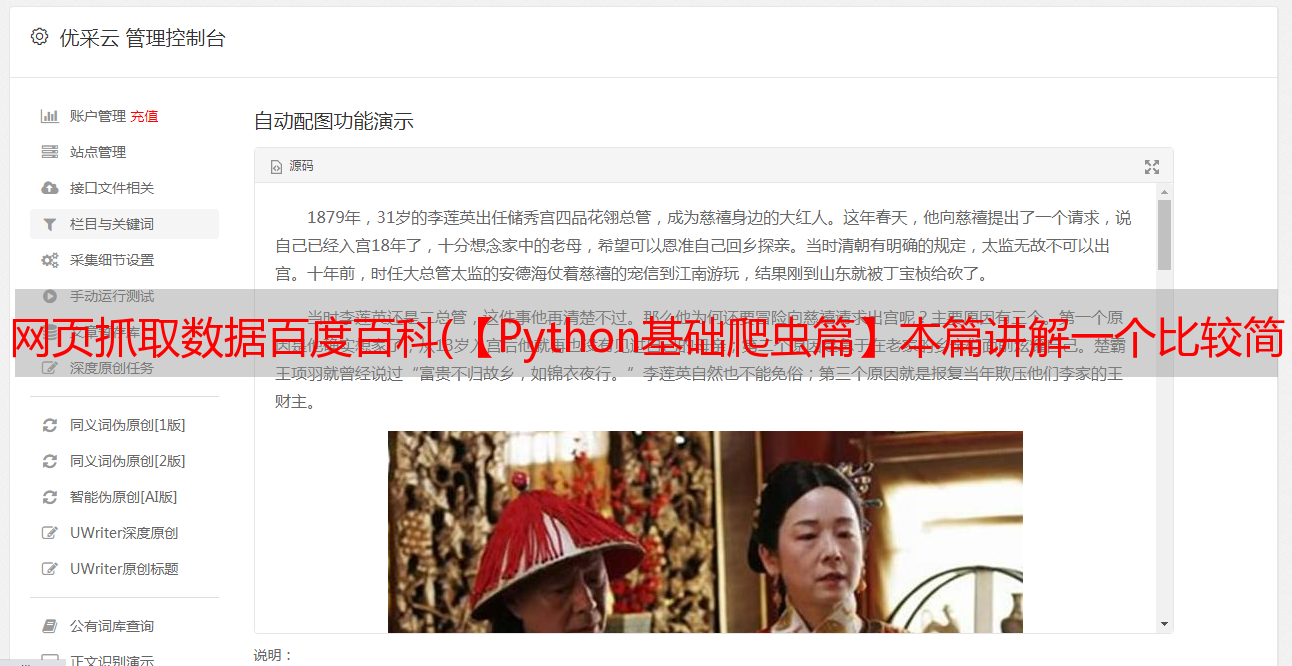
当然你也可以尝试爬取你想爬取的网络数据~
如果有帮助,请点个赞~

