爬虫抓取网页数据(网络爬虫系统的原理和工作流程及注意事项介绍-乐题库)
优采云 发布时间: 2021-10-28 16:16爬虫抓取网页数据(网络爬虫系统的原理和工作流程及注意事项介绍-乐题库)
网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集的图片、音频、视频等文件或附件,可以自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
在大数据时代,网络爬虫对于采集来自互联网的数据来说更是一种优势工具。已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。网络爬虫的原理 网络爬虫是按照一定的规则自动抓取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
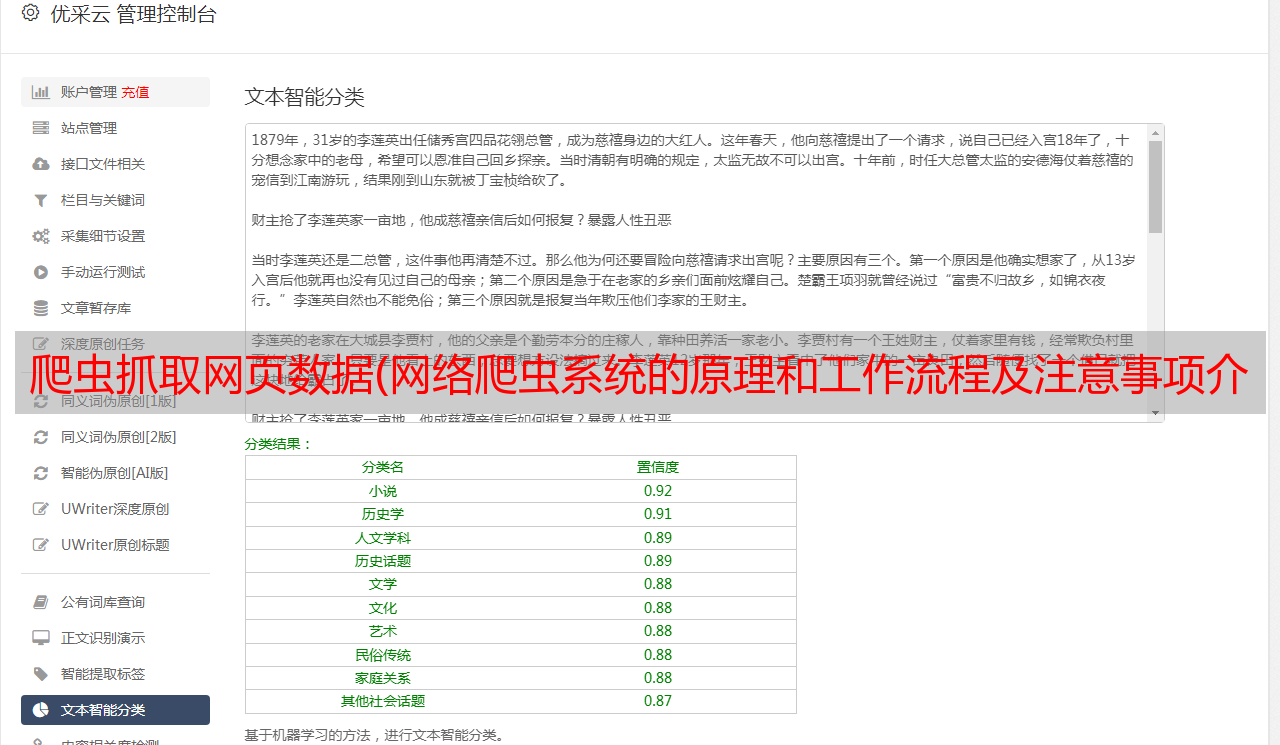
图1 网络爬虫*敏*感*词*
除了供用户阅读的文本信息外,网页还收录一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些输出度(网页中超链接的数量)较高的比较重要的URL作为*敏*感*词*URL集合。
网络爬虫系统使用这些*敏*感*词*集作为初始 URL 开始数据爬取。由于网页收录链接信息,因此可以通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个*敏*感*词*URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法遍历所有或深度优先搜索算法页面。
由于深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索离网站首页较近的网页信息,所以广度优先搜索算法一般为用于 采集 网页。
网络爬虫系统首先将*敏*感*词*URL放入下载队列,简单地从队列头部取一个URL下载对应的网页,获取网页内容并存储,解析网页中的链接信息后,可以获得一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后取出一个URL,下载其对应的网页,然后解析,如此循环往复,直到遍历全网或满足某个条件,才会停止。网络爬虫的工作流程如图2所示。网络爬虫的基本工作流程如下。
1)首先选择*敏*感*词*URL的一部分。
2)将这些URL放入URL队列进行爬取。
3) 从待爬取的URL队列中取出待爬取的URL,解析DNS得到主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些 URL 放入爬取的 URL 队列中。
4)对抓取到的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入待抓取的URL队列中,从而进入下一个循环。
图2 网络爬虫的基本工作流程
网络爬虫抓取策略谷歌、百度等通用搜索引擎抓取的网页数量通常以亿为单位计算。那么,面对如此多的网页,网络爬虫如何才能尽可能地遍历所有网页,从而尽可能扩大网页信息的覆盖范围呢?这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,爬取策略决定了爬取网页的顺序。
本节首先简单介绍一下网络爬虫的爬取策略中用到的基本概念。1)网页之间的关系模型 从互联网的结构来看,网页通过数量不等的超链接相互连接,形成一个庞大而复杂的相互关联的有向图。
如图3所示,如果把网页看成图中的某个节点,把网页中其他网页的链接看成这个节点到其他节点的边,那么我们就很容易看到整个Internet 网页被建模为有向图。
理论上,通过遍历算法遍历图,几乎可以访问互联网上的所有网页。
图3 网页关系模型图
2)网页分类从爬虫的角度来划分互联网。互联网上的所有页面可以分为5个部分:已下载和未过期网页、已下载和已过期网页、待下载网页、已知网页和不可知网页,如图4所示。
获取的本地网页实际上是互联网内容的镜像和备份。互联网是动态变化的。当互联网上的部分内容发生变化时,抓取到的本地网页就会过期。因此,下载的网页分为两种:下载的未过期网页和下载的过期网页。
图4 网页分类
待下载的页面指的是URL队列中待抓取的页面。
可以看出,网页指的是尚未被抓取的网页,不在待抓取的URL队列中,但可以通过分析抓取的页面或待抓取的URL对应的页面来获取。
还有一些网页是网络爬虫不能直接抓取下载的,称为不可知网页。
下面重点介绍几种常见的爬取策略。1. 万能网络爬虫 万能网络爬虫又称全网爬虫。爬取对象从一些*敏*感*词*网址扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集数据。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个链接地跟随它,直到无法再深入为止。
爬行完成一个分支后,网络爬虫返回上一个链接节点,进一步搜索其他链接。当所有的链接都遍历完后,爬取任务结束。
这种策略更适合垂直搜索或站内搜索,但在抓取页面内容更深层次的网站时会造成资源的巨大浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间中。那个时候,它会尽量走,只有在找不到一个节点的后继节点时才考虑它的兄弟节点。
这样的策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它会沿着一条路径无限扩展,从而“陷入”海量数据。一般情况下,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样就降低了搜索的效率。因此,一般在搜索数据量较小时采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录级别的深度抓取页面,优先抓取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。
仍以图3为例,遍历的路径为1→2→3→4→5→6→7→8
由于广度优先策略是在第N层节点扩展完成后进入第N+1层,所以可以保证最短路径找到解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支爬取无法结束的问题,实现方便,无需存储大量中间节点。缺点是爬到更深的目录层次需要很长时间。页。
如果搜索过程中分支过多,即该节点的后续节点过多,算法就会耗尽资源,在可用空间中找不到解。2. 专注于网络爬虫专注于网络爬虫,也称为主题网络爬虫,是指选择性抓取与预定义主题相关的页面的网络爬虫。
1) 基于内容评价的爬取策略
DeBra在网络爬虫中引入了文本相似度的计算方法,提出了Fish Search算法。
该算法以用户输入的查询词为主题,将收录查询词的页面视为与该主题相关的页面。它的局限性在于它无法评估页面与主题的相关性。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面与主题之间的相关性。
使用基于连续值计算链接值的方法,不仅可以计算出哪些抓取的链接与主题相关,还可以量化相关性的大小。
2) 基于链接结构评估的爬行策略
网页不同于一般文本。它是一种收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面中的链接表示页面之间的相互关系。基于链接结构的搜索策略模型利用这些结构特征来评估页面和链接的重要性来确定搜索顺序。其中,PageRank算法是这类搜索策略模型的代表。
PageRank算法的基本原理是,如果一个网页被多次引用,它可能是一个非常重要的网页。如果一个网页没有被多次引用,而是被一个重要的网页引用,那么它也可能是一个重要的网页。一个网页的重要性均匀地传递给它所指的网页。
将某个页面的PageRank除以该页面存在的前向链接,将得到的值与前向链接指向的页面的PageRank相加,即得到链接页面的PageRank。
如图 5 所示,PageRank 值为 100 的网页将其重要性平均传递给它引用的两个页面,每个页面获得 50。同样,PageRank 值为 9 的网页将其重要性传递给三个引用的页面. 为页面的每一页传递的值为 3。
PageRank 值为 53 的页面的值来自引用它的两个页面传递的值。
,
图 5 PageRank 算法示例
3) 基于强化学习的爬行策略
Rennie 和 McCallum 将增强学习引入聚焦爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性,从而确定链接访问的顺序。
4) 基于上下文映射的爬取策略
勤奋等。提出了一种爬行策略,通过建立上下文映射来学习网页之间的相关性。该策略可以训练机器学习系统,通过该系统可以计算从当前页面到相关网页的距离。3. 增量网络爬虫 增量网络爬虫是指对下载的网页进行增量更新,只抓取新生成或变化的网页的爬虫。它可以在一定程度上保证被爬取的页面尽可能的新。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要重新访问网页以更新本地页面集中页面的内容。常用的方法有统一更新法、个体更新法和基于分类的更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常用的策略包括广度优先策略、PageRank 优先策略等。4. 深网爬虫网页按存在方式可分为表层网页和深层网页。
深度网络爬虫架构由6个基本功能模块(爬虫控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS表)组成。
其中,LVS(LabelValueSet)表示标签和值的集合,用于表示填写表单的数据源。在爬虫过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。

