利用采集插件实现网站内容的自动化填充(图)
优采云 发布时间: 2021-02-13 10:00
利用采集插件实现网站内容的自动化填充(图)
先前的文章文章解释了垃圾网站的情况,其中提到了一种特殊的垃圾网站,即使用采集插件来实现网站。
作者以前没有做过采集。我计划最近建立一个资源共享站点。由于资源物资太大,我自己做,所以我花了300元钱请人来制作采集。不难发现,今天我将与您分享。
一、了解采集个插件
如果您想很好地使用采集工具,则必须首先知道哪些采集工具可用。如果您的网站是用各种开源系统构建的(对于开源系统,请参阅我以前的文章),通常会有相应的采集插件以及一些知名的采集软件。
在采集上,作者不是专业人士。我将只分享作者今天使用的优采云 采集软件。它不作为插件存在,而是作为独立软件存在,只能在Windows上运行。在系统中。
要使用优采云 采集,您需要了解如何配置发布者以及如何配置采集对象。所谓的发布端是您自己的网站,所谓的采集对象是您要提供的特定采集对象的页面内容。
二、如何配置发布者
因为它是由有钱人制作的,所以这部分正是作者无法清楚解释的,因为发布模块设置了访问密码。
由于作者付钱给某人,所以有理由相信该模块的生产者也在努力保护自己的劳动成果。但是与此同时,我还找到了一个网站发行模块,可以下载各种开源系统。
与此同时,在网站中还存在许多用采集函数编写的学习课程文章。有兴趣的朋友可以更深入地挖掘。如果您不想进一步研究,可以查看是否使用了网站系统的发布模块。
三、如何配置采集终端
我不得不说,作者也很懒,没有自己研究采集,只是根据其他人的规则研究了它。
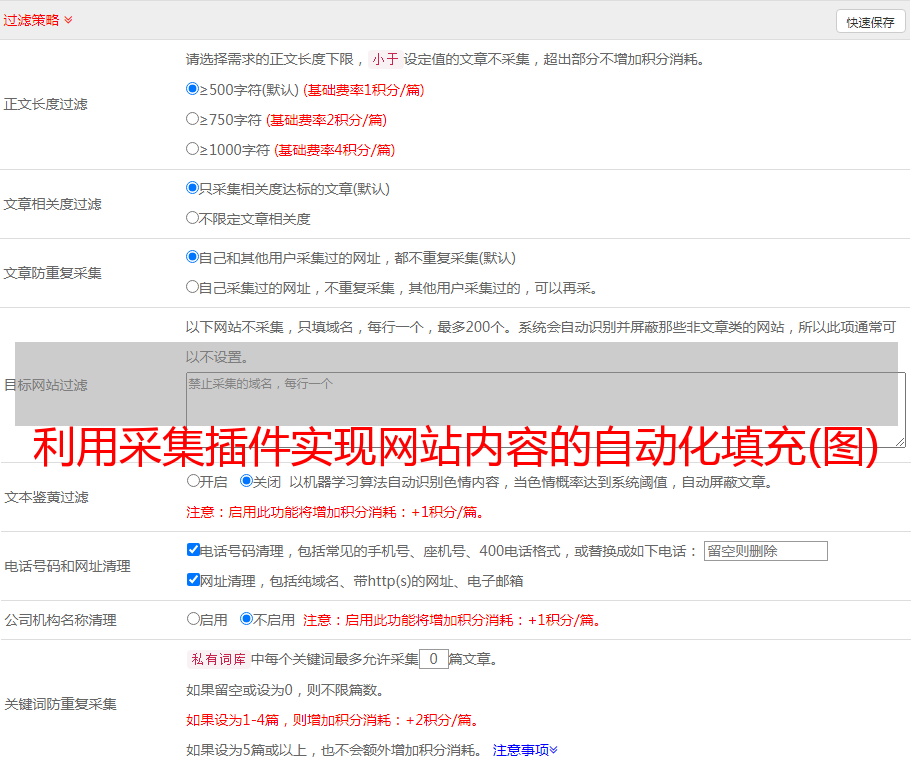
从上面的屏幕截图中可以看到,这是采集配置的第一位。左侧的“ 1级列表页面”表示采集的页面只有一个级别列表。下一步是干货!
1、提取规则中的代码在哪里?
·通过浏览器(即我们需要采集内容的页面)打开起始URL
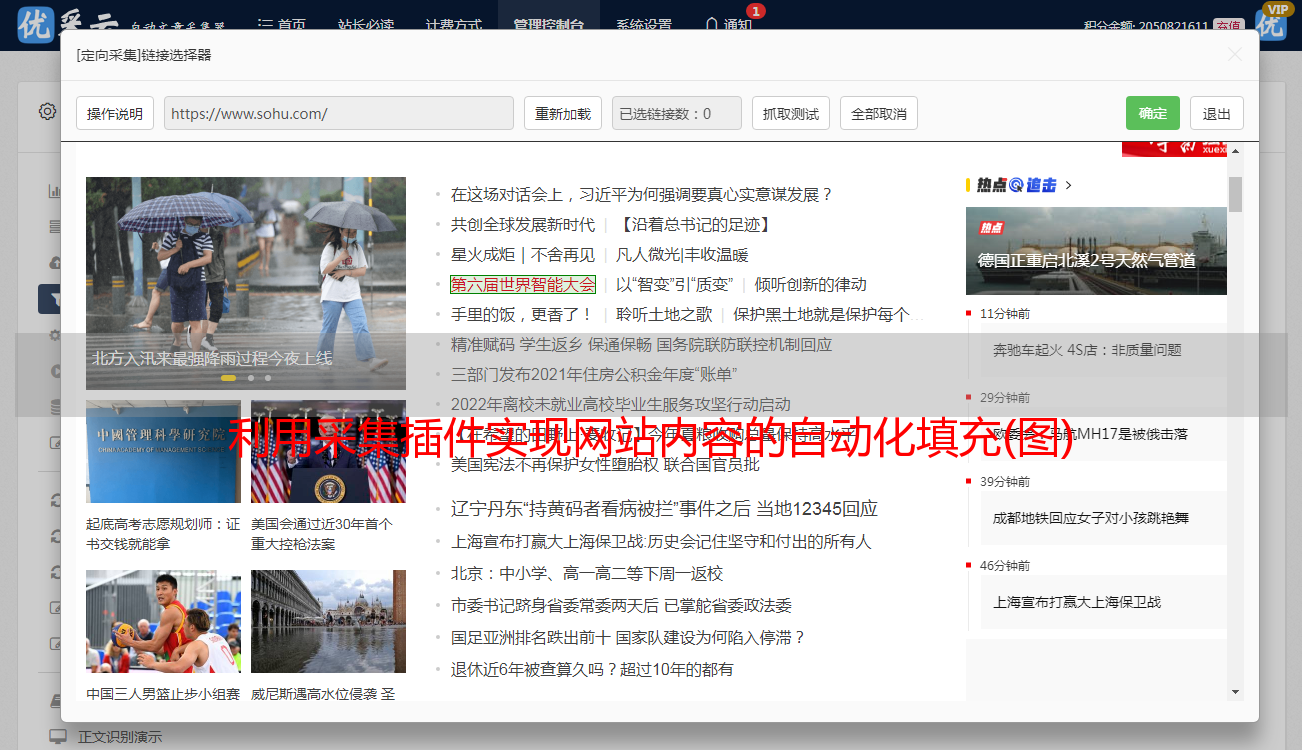
·在打开的页面上按F12(Windows计算机)以调用网页调试
·选择小箭头(Mac与Windows系统不同,请自行查找)
·选择页面上的内容区域
仔细比较此处的代码是否与提取规则中的代码完全相同?没错,提取规则是使用此内容作为入口。同时,提取该缩略图以用作您自己的网站发布缩略图。
注意:[parameter]标签是要提取的信息,(*)标签代表被忽略的信息。
2、在哪里可以找到设置区域?
我们现在仍然使用此方法,这次我们使用小箭头选择整个列表页面:
让我们再次比较
另一个实际上是翻页标签。要知道此列表有很多页面,采集系统需要确定转到页面的位置:
此外,还需要完成一些配置,但是基本操作方法相似。如下图所示:
3、内容采集规则
请注意,上面的标签列表对于每个人都是不同的,只有标题和内容是通用的。在这里,我主要讨论标题和内容的提取:
首先,我们必须进入采集对象的文章内容页面,然后使用与之前相同的方法来获取源代码部分。通常,标题默认情况下将位于head标签中(如果您不知道head标签是什么,您可以阅读我以前关于前端集成的文章简介):
因此,请填写固定标签:“标题”:“ [参数]”!如下图所示:
表示读取title:标签后面的参数。请注意,此处的选择是常规提取,即从特定内容采集中提取我们需要的参数。请注意,屏幕截图下方有数据处理。什么意思?
从屏幕截图中可以看到,毕竟,这是来自其他人的网站 采集内容。别人不可避免地会带上自己的网站标志,我们自然不希望使用别人的内容来使用它。如果其他人的网站表示,则我们需要使用数据处理功能自动替换我们要替换的某些内容。
您可以看到其中有许多高级替换功能。如果要删除它,只需遵循删除规则。您可以自己学习其他规则。
注意:数据处理可以同时添加多个规则,并且可以同时处理多个替换功能。
下面介绍内容采集。在内容区域中,我们选择在前后截取。这是什么意思?通过定义头和尾,采集头和尾之间的所有内容:
上面第一个框中截获的代码是开头,第二个框中截获的代码是结尾。因为代码是折叠的,所以您可能看不到详细的代码,但是您不需要它。浏览器的绿色和蓝色区域可以看到文章的整个内容区域实际上已被拦截。
填写开头和结尾字符串。然后在数据替换中,为了防止以代码形式将采集中的信息以采集的形式传递给我们自己网站,我们需要做一些数据处理以使采集的内容尽可能简单可能的文字!其中,HTML标记排除应用程序可以排除某些我们不希望采集访问的内容:
其他采集对象需要基于实际发布项目为采集,并且一般规则相似!最后,测试并发布采集,知道一点计算机的小白可以自己触摸它! (无论如何,编辑器以前从未接触过采集,并且有一个可供参考的模型!)
四、结论
编辑器以前从未玩过采集。第一次触摸它时,我觉得它真的很方便,因此我在不知不觉中分享了它!作为一个教程,它有一些缺点,那就是让每个人都有一个基本的了解。如果您想系统地学习,可以找到一些采集资料来学习!最后,为了说明一点,本文演示的采集对象仅用于演示织梦 58网络理解。
请正确,合理和合法地使用采集功能。跟我来学习更多小白可以学习的网络知识。如有任何疑问,可以留言咨询!

